
经常需要在 android 的 fullsource 上合入大量代码,一般提供的代码包都是新旧代码和 patch,代码一般不是基于要合入的 android 制作的,所以就是 patch 的上下文一般有所不同,没法直接使用 patch 工具,一般大家都是使用 Beyond Compare 等工具来人工对比合入。这样做的缺点是,如果代码量很大,容易漏掉文件,或者人工疏忽合错代码。
最近公司基础流程中需要加入多平台 fullsource 验证流程,由于平台很多,验证很频繁,采用原来的方式来做的话,合代码时间太长,还容易出现疏忽。 所以,就在想如何将这部分工作自动化。
patch的问题
patch命令可以将来自于源文件的改修,同步到目标文件中。
patch命令会根据patch文件的上下文信息,在目标文件中找到合适的位置,插入patch。
但是如果源文件和目标文件的上下文有些差别,那么经常会遇到patch失败的情况。
比如原文件和patch如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# a.c
aa
bb
cc
# b.c
aa
bb
dd
cc
# patch文件diff.patch(diff -U10 a.c b.c > diff.patch)
--- a.c 2018-05-14 16:33:23.133303425 +0800
+++ b.c 2018-05-14 16:33:51.484964501 +0800
@@ -1,3 +1,4 @@
aa
bb
+dd
cc
比如将a.c改成下面这样,看看还能否成功:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# a.c
aa
bb
cc
# 运行提示
>> patching file a.c
>> Hunk #1 succeeded at 1 with fuzz 2.
# 打完patch的a.c
aa
dd
bb
cc
可以看到,本应该在bb后面的dd,现在跑到bb前面去了
其实这种情况,在我们使用patch的时候,经常遇到,因为源文件和目标文件有些空行区别是很正常的事情
再比如下面这种情况,在bb和cc后面,各加了一个空格,然后在bb前面插入了一些空行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# a.c, bb和cc后面各加了一个空格
aa
bb
cc
# 运行结果
patching file a.c
Hunk #1 succeeded at 1 with fuzz 2.
# 打完patch的a.c
a
dd
bb
cc
可以看到,这样打得也不对
这种情况也经常出现,patch同样处理不了这种情况。
但是其实上述的情况都应该是可以避免的,毕竟实际代码没有什么本质的区别。
一种思路
既然这些空格和空行,都不是我们关心的,而且对代码逻辑也没有实际的影响,那么我们就可以想办法忽略掉他们的影响,找到真正的插入patch的位置。
一种方式
- 先确定一个行数,作为我们需要对比的上下文,比如3,也就是我们选择上下各3行
- 将patch中待插入代码的上下各3个非空行,提取出来,注意哦,这里只要非空行
- 将这6行合并在一起,去掉换行和所有空格、TAB,做出一个字符串s_origin
- 从上到下扫描目标代码,对每6个非空行,进行一次第三步的操作,然后将结果和s_origin对比下,得到一个相似度百分比。
- 将相似度最大的6行作为待插入的区域,将待插入代码插入到这6行中的第3行后面。
原理很简单吧,实际操作起来效果也不错,上面提到的patch问题,都可以解决掉。
有一点没有解释,如何计算相似度百分比?
如果大家很熟悉相关的算法,那么就按自己的方式处理就好了。
我是不太熟悉,幸运的是,python默认库中就有这种函数,代码如下:
1
2
3
import difflib
def compute_diff(str1, str2):
return difflib.SequenceMatcher(None, str1, str2).ratio()
这种处理方式,是我最开始使用的,虽然大部分效果不错,但是有时也会出现一些问题。
出现问题的原因是,这种方式,是将6行数据整体来做比较的,有时前3行完全一致,但是后3行差距比较大,这时计算出来的相似度就不会很高,而有些是前3行和后3行都一些不同,但是不同的地方差距不是很大,这样计算出来的相似度就比上一种情况要高,程序默认选择了后种。
那么这种选择好不好呢?
从实践中来看,这种选择并不好,因为大家在自己合patch的时候,就会体会到,如果发现一个位置,前几行是完全一致的,而后几行有些区别,或者后几行完全一致,前几行有些区别,那么在这点插入代码是比前后都有些不同的位置点插入更为合适的。
所以另一种方式
- 将patch中的非空6行,分为前后各3行
- 对这前后各3行,分别做出来s_origin_before和s_origin_after
- 从上到下扫描目标代码,对每6个非空行,分为前后各3行,分别与s_origin_before、s_origin_after进行相似度对比,得到两个相似度百分比,prop_before,prop_after
- 将这两个百分比转换成分数,百分比越接近100%,那么分数应该越高,这里不是线性的。
- 根据两个分数,计算平均值,选择平均值最大的点,插入代码。
同样解释下:
为什么转换成分数的时候,不用线性的函数? 因为可以这样考虑,如果线性的话,我们假设1%对应的是1分的话,那么100%(前)和30%(后),会得到130分,而80%和80%会得到160分,这不是我们希望的,我们希望的是如果有一方达到100%相似,我们就要很倾向于这个点。
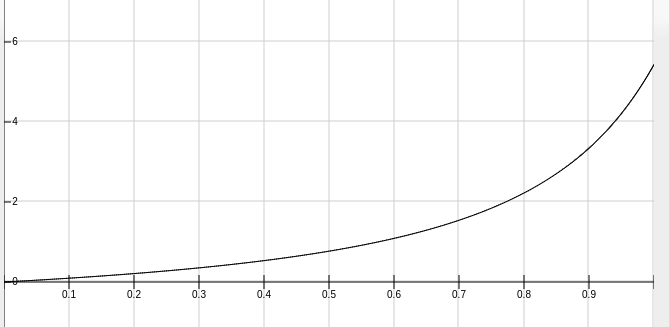
所以我这里使用的函数是下面这个:
1
math.exp(1 / (1.5 - prop)) - math.exp(1 / 1.5)
![]()
可以看到,在1(也就是100%相似)的时候,大概可以得到5这个很大的分数。
这个函数,实际使用起来效果还不错,大家也可以选择别的函数。
到目前为止,我在项目中使用的就是上面这种方式,在前一种方式出错的地方,现在这种方式都可以正确处理,效果还不错,大幅提高了patch的可用性,也为节省了大量的时间。
最后提到一点,在实际使用中,为了保险起见,建议对所有不是100%匹配的地方,都进行下人工check,毕竟以防万一。
到这就差不多了,主要是提供一种解决类似问题的思路,希望对大家有用。
代码地址:
https://github.com/cooli7wa/script_github/tree/master/mine/shell/android_helper
(find_best_place.py)