
比特币的 PoW 算法,之前的文章中已经提到,以太坊目前使用的共识算法 (Ethash) 虽然也是 PoW,但是与比特币的不同。
bitcoin 的 PoW 算法
比特币的工作量证明算法,可以用下面这个公式表示:
1
2
hash_output = sha256(prev_hash, merkle_root, nonce)
hash_output 应该不大于 nBits
- prev_hash,前一个区块的 hash,固定值。
- merkle_root,默克尔树的根,每个矿工计算出来的都不一样,但是同一个矿工每次计算都一致。
- nonce,如果 hash 计算的结果大于 nBits,那么矿工就会改变 nonce 的值,重新计算 hash。
(这里没考虑 extern_nonce)
这个算法的实现很简单,很容易理解,很符合共识算法的特点,求解困难验证容易,至今也运行良好,但是慢慢显现出来一些弊端:
求解过程完全依赖 CPU 的计算能力 ,所以出现了很多针对 hash 优化的芯片,即 ASIC。
新的硬件抛弃了通用性,只做 hash,因而大幅提升了求解的速度,为了追上大家的速度,矿场只能升级硬件,这导致大批量的矿机过时,而专用的芯片只能保持一段时间的领先,在大家都升级之后,又变得毫无优势,另外关键的是这种芯片只能用来挖矿,还有其他用途么?
另外这种硬件很昂贵,普通的家用电脑越来越难与之对抗,算力越来越集中于少数资金雄厚的矿场手中。
普通人目前只能通过加入矿池才有机会。其实这种矿工,根本算不上矿工,因为所有的数据都是由矿池提供的,自己只是计算 hash,相当于这个庞大计算机中的一个 cpu 而已,实际控制权都在矿池,也导致了算力越来越集中。
其实矿池的出现也是因为算法,因为其中变化的变量只有 nonce 一个,其他都是固定的,所以可以没有区块数据,可以不用大内存,甚至可以没有硬盘,只要能满足计算 hash 的需求即可。
另外所需的存储空间也很大,现在 200 多 G,这已经超过大多数手机的存储空间,这也限制了挖矿的人群。
正因为这些问题,才发明了后续的很多算法。
ETH 的 PoW 算法,Ethash
Ethash 的前身是 Dagger Hashimoto,而 Dagger Hashimoto 的前身是 Dagger 和 Hashimoto 算法。
将前面说的问题总结下,这些也是这些算法要解决的问题:
- 抵制矿机(ASIC)。
- 全链数据存储。前面说的矿池的例子。
- 轻客户端。前面说的手机的例子。
我们看下 hashimoto 和 ethash,dagger 包含在了 ethash 里面。
1. Hashimoto
Hashimoto I/O bound proof of work,基于 I/O 带宽的工作量证明算法。
Hashimoto 由 hash, shift, modulo 组成。
直接看下算法代码
1
2
3
4
5
6
7
8
9
10
11
12
13
# hash
hash_output_A = sha256(prev_hash, merkle_root, nonce)
for i = 0 to 63 do
# shift
shifted_A = hash_output_A >> i
# mode
transaction = shifted_A mod total_transactions
# I/O
txid[i] = get_txid(transaction) << i
end for
txid_mix = txid[0] ⊕ txid[1] … ⊕ txid[63]
final_output = txid_mix ⊕ (nonce << 192)
final_output 应该不大于 nBits
sha256 的结果不直接与 nBits 比较了,而是作为了中间变量。下面的循环里,调用了 get_txid,这个函数获取对应编号的 transaction 的 id 值,这个 transaction 是从内存或磁盘里取出来的,所以这里是 I/O 操作。然后在将获取到的 id 异或得到最终的 output,将这个与 nBits 比较。
这个算法解决了上面说的 1 和 2 的问题,是怎么解决的?
首先,求解过程不只是 hash 了,还需要一些读取操作,大量的时间消耗在了 I/O 操作上,所以单纯的 ASIC,只是提高了求 hash 的速度,无法使整体获得很大的提升。那么可以用告诉存储介质来提升速度,确实是,可以制作超高速的内存或者固态硬盘,但是那么容易么?这个目标是现在所有内存或者固态硬盘厂家的目标,现在这么多厂家都没解决的问题,可能短时间做到么?不可能的,那 ASIC 是怎么回事?因为只计算 hash 这个目标和 CPU 厂家的目标是不同的, CPU 厂家的目标是通用性,而不是这一个算法。这个解决了 1 的问题。
然后,还是因为 I/O,考虑矿池的情景,大量的矿工因为没有区块链数据,只能通过网络向矿池请求数据,在一次计算中,这种请求就有 64 次,多次计算,这种请求的总数就很客观,矿池为了应付庞大数量的请求必然需要投入非常多的硬件成本,这就不划算了,还不如大家自己保存区块链数据。另外网络延迟也是一种消耗。这个解决了 2 的问题。
而且,在这种算法下,矿工需要保存完整的区块链数据,哪怕只少了一个区块,也会导致挖矿成功的概率降低很多。文章中举了一个例子,假设一共 100 个区块,少了 1 块,那么就需要 2 倍的 hash 次数,少了 2 块,就需要 4 倍,这个很好理解,想了解的可以看下 这个文章。
2. ethash
我们直接看下源码,从入口开始看:
Seal,consensus/ethash/sealer.go
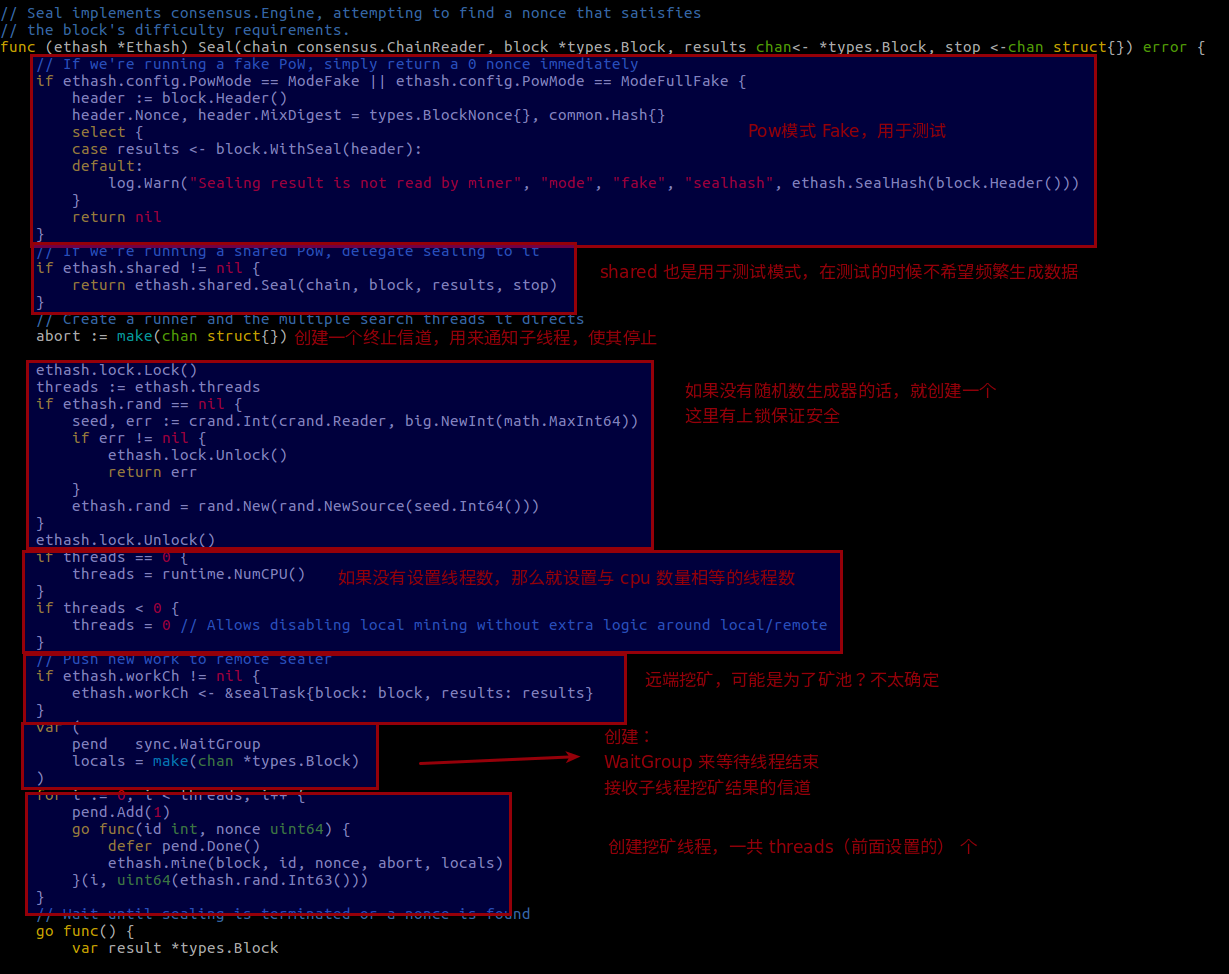

这个函数主要是创建和子线程的控制,然后我们看下同一个文件的 mine 这个函数:
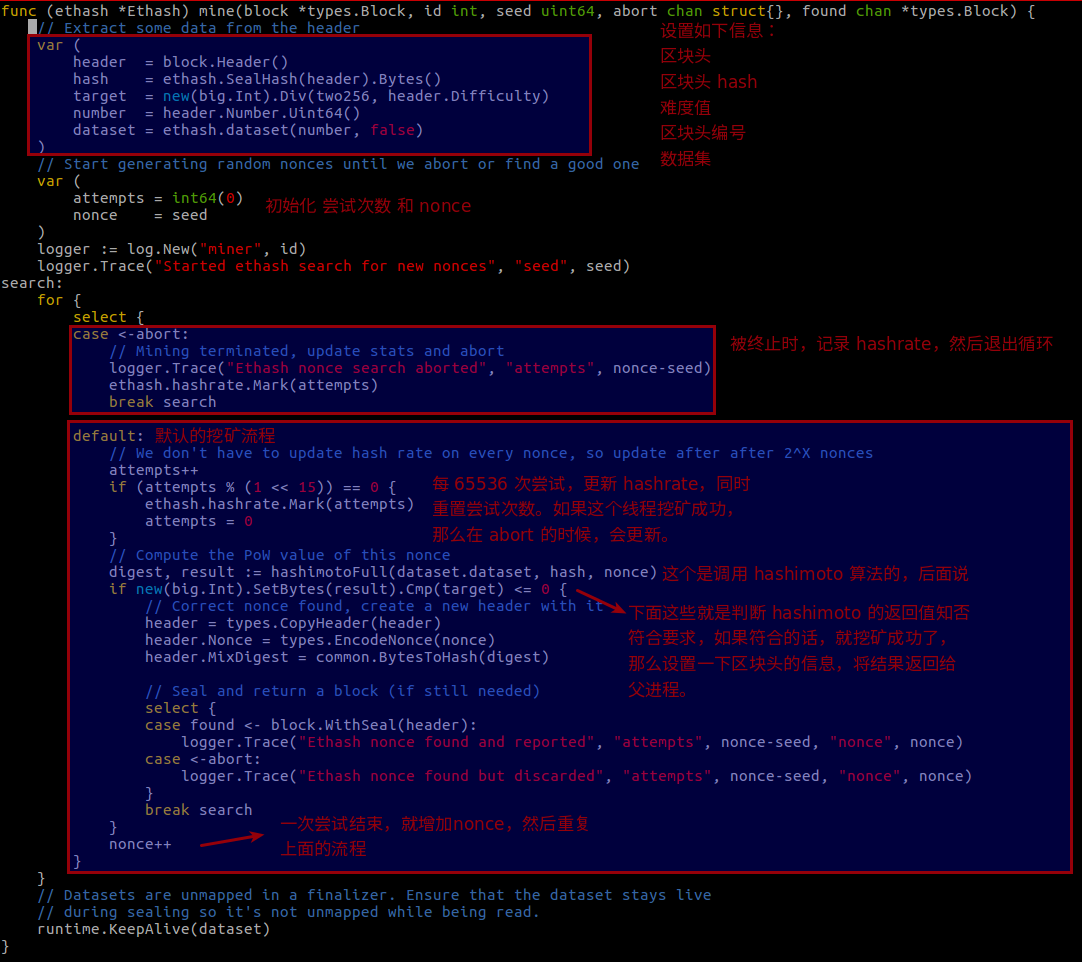
其中的 hashimotoFull,这个名字很熟悉了,前面介绍过 hashimoto 的算法,这里的算法实现和之前的有所区别,主要是这里使用的数据集不再是整个区块链,而是叫做 DAG 的数据集,这个后面再说。
hashimotoFull,consensus/ethash/algorithm.go
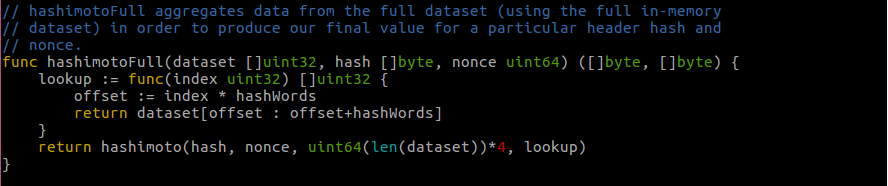
这函数主要是创建了一个闭包函数,传递给了 hashimoto,这个闭包函数在根据传进来的参数,在数据集中选择特定的数据。
看下还是在这个文件内的 hashimoto 函数
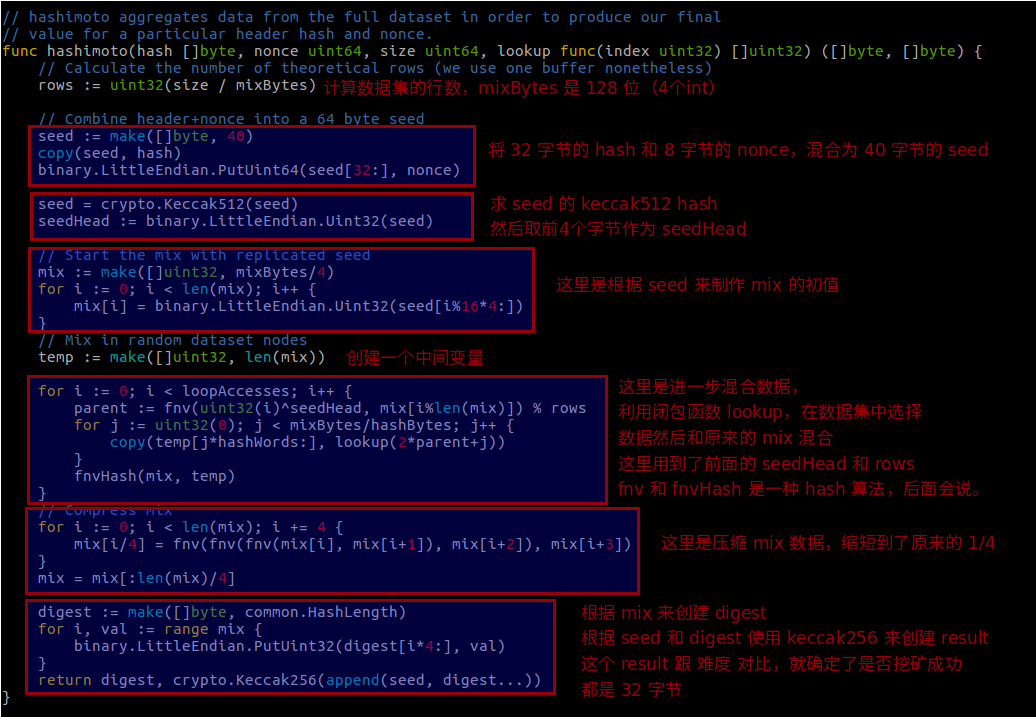
简单介绍下 FNV,FNV 是一种哈希算法,具有高离散性,特别适用于哈希非常相似的字符串,函数如下,还是在这个文件里:
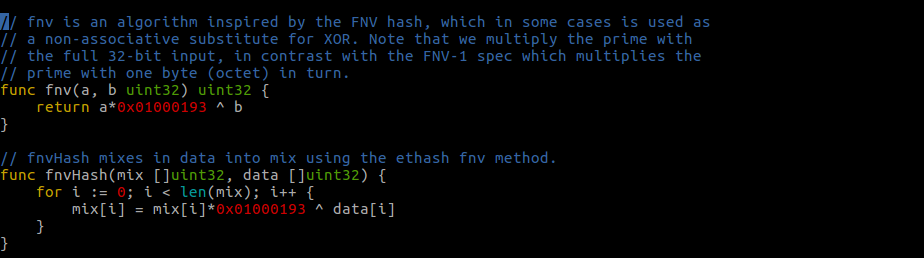
到这里整个挖矿的流程就介绍完了。
3. DAG
ethash 与传统 hashimoto 不同的地方,主要是使用了特殊的数据集 DAG,而生成 DAG 需要先生成 cache。
这里面有几个基础概念,先介绍下。
epoch。每 30000 个区块,叫做一个 epoch,“一世”,按照 12 秒一个区块的速度,大概是 100 小时。
1 2
epochLength = 30000 epoch := block / epochLength
cache/DAG 的生成周期。因为生成 DAG 很慢,所以在一定周期内,DAG/cache 都是复用的,每个 epoch 重新生成一次。DAG 依赖 cache,cache 依赖 seed,而 seed 只和区块高度有关,所以可以预先生成。
1
seed := seedHash(c.epoch*epochLength + 1)
cache/DAG 的大小。大小是不固定的,epoch 在 2048(区块高度在 61440000)之前,是按照写死的数组里的数来得到 size,在之后是按照一个公式来计算,我们看下代码片段:
1 2 3 4 5 6 7 8
func (d *dataset) generate(dir string, limit int, test bool) { ... csize := cacheSize(d.epoch*epochLength + 1) dsize := datasetSize(d.epoch*epochLength + 1) ... generateCache(cache, d.epoch, seed) generateDataset(d.dataset, d.epoch, cache) ...
1 2 3 4 5 6 7
func cacheSize(block uint64) uint64 { epoch := int(block / epochLength) if epoch < maxEpoch { return cacheSizes[epoch] } return calcCacheSize(epoch) // 超过 2048 epoch,用这个函数计算 }
1 2 3 4 5 6 7
func datasetSize(block uint64) uint64 { epoch := int(block / epochLength) if epoch < maxEpoch { return datasetSizes[epoch] } return calcDatasetSize(epoch) // 超过 2048 epoch,用这个函数计算 }
1 2 3 4 5 6 7
func calcCacheSize(epoch int) uint64 { size := cacheInitBytes + cacheGrowthBytes*uint64(epoch) - hashBytes for !new(big.Int).SetUint64(size / hashBytes).ProbablyPrime(1) { // Always accurate for n < 2^64 size -= 2 * hashBytes } return size }
1 2 3 4 5 6 7
func calcDatasetSize(epoch int) uint64 { size := datasetInitBytes + datasetGrowthBytes*uint64(epoch) - mixBytes for !new(big.Int).SetUint64(size / mixBytes).ProbablyPrime(1) { // Always accurate for n < 2^64 size -= 2 * mixBytes } return size }
可以看到,在 2048 epoch (区块高度 61440000) 之前,实际上就是在数组里取值,数组是这样的:
![]()
![]()
现在 ETH 的区块高度为 6365581,对比下 61440000,这些数想要用完还得很久很久,到 2048 的时候,cache 和 DAG 的大小分别为:
1 2 3 4
DAG: 18245220736/8/1024/1024 = 2174.999,大概 2G cache: 285081536/8/1024/1024 = 33.984,大概 33MB
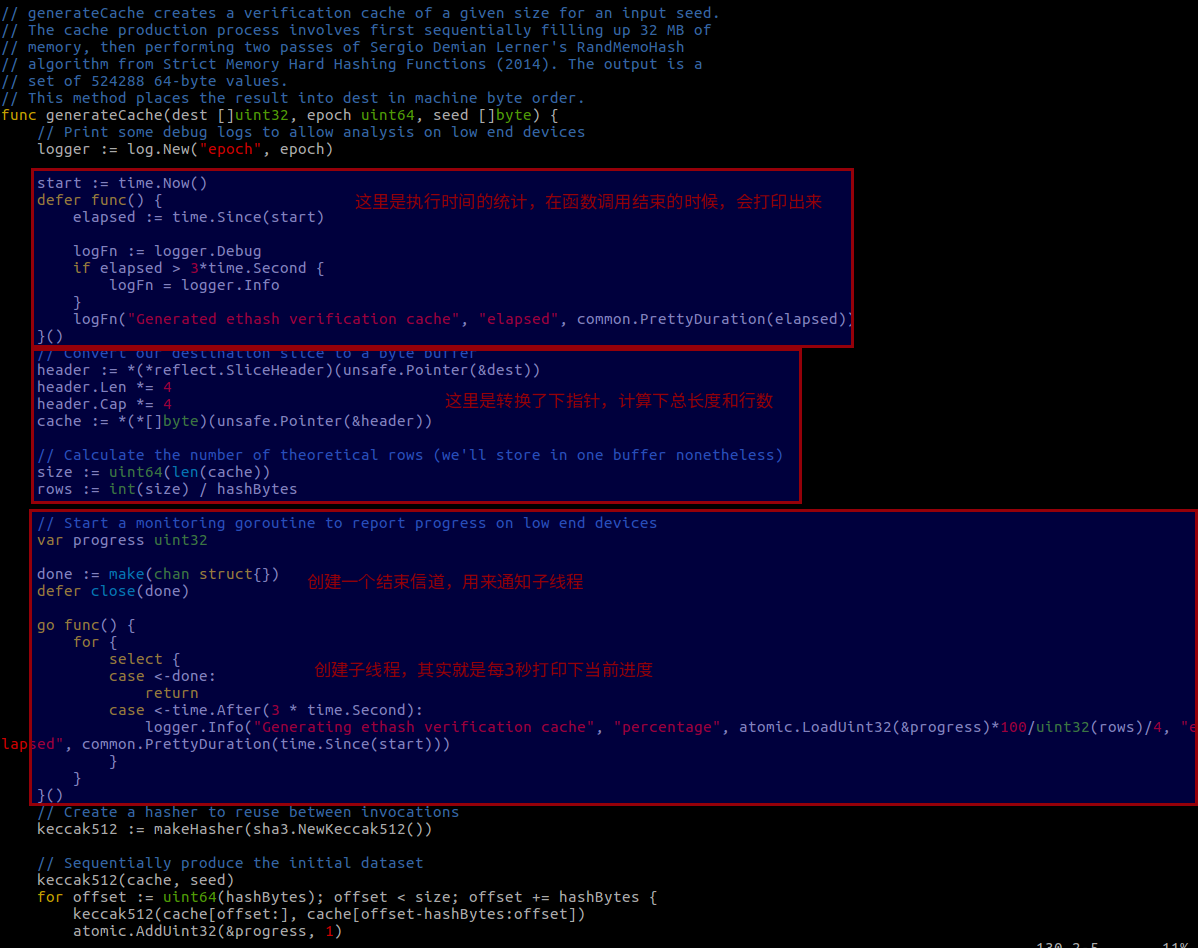
这些说完了,我们先看下生成 cache 的代码,generateCache (consensus/ethash/algorithm.go)
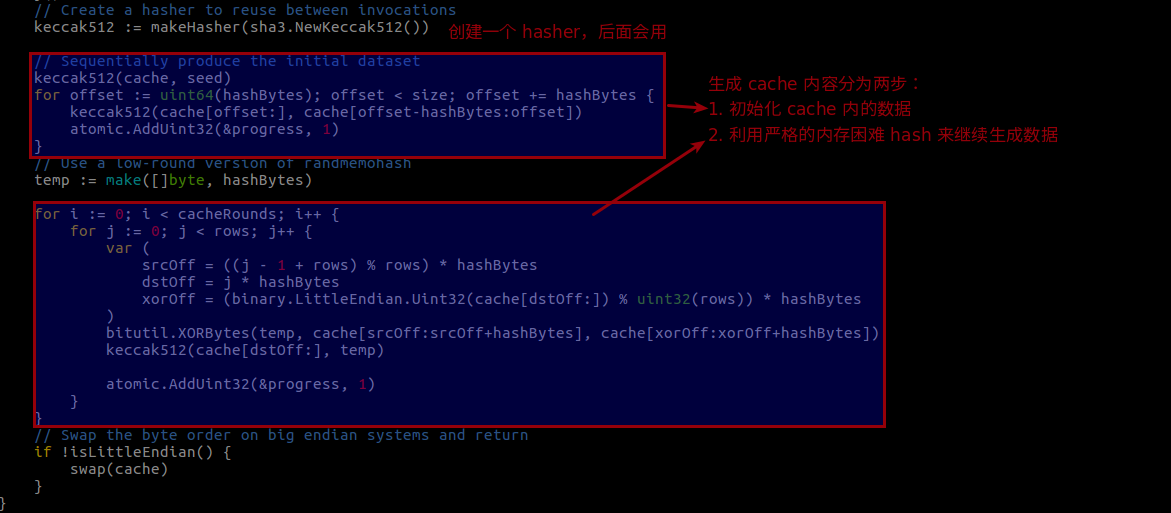
接下来看看 dataset 生成的代码,generateDataset (consensus/ethash/algorithm.go)
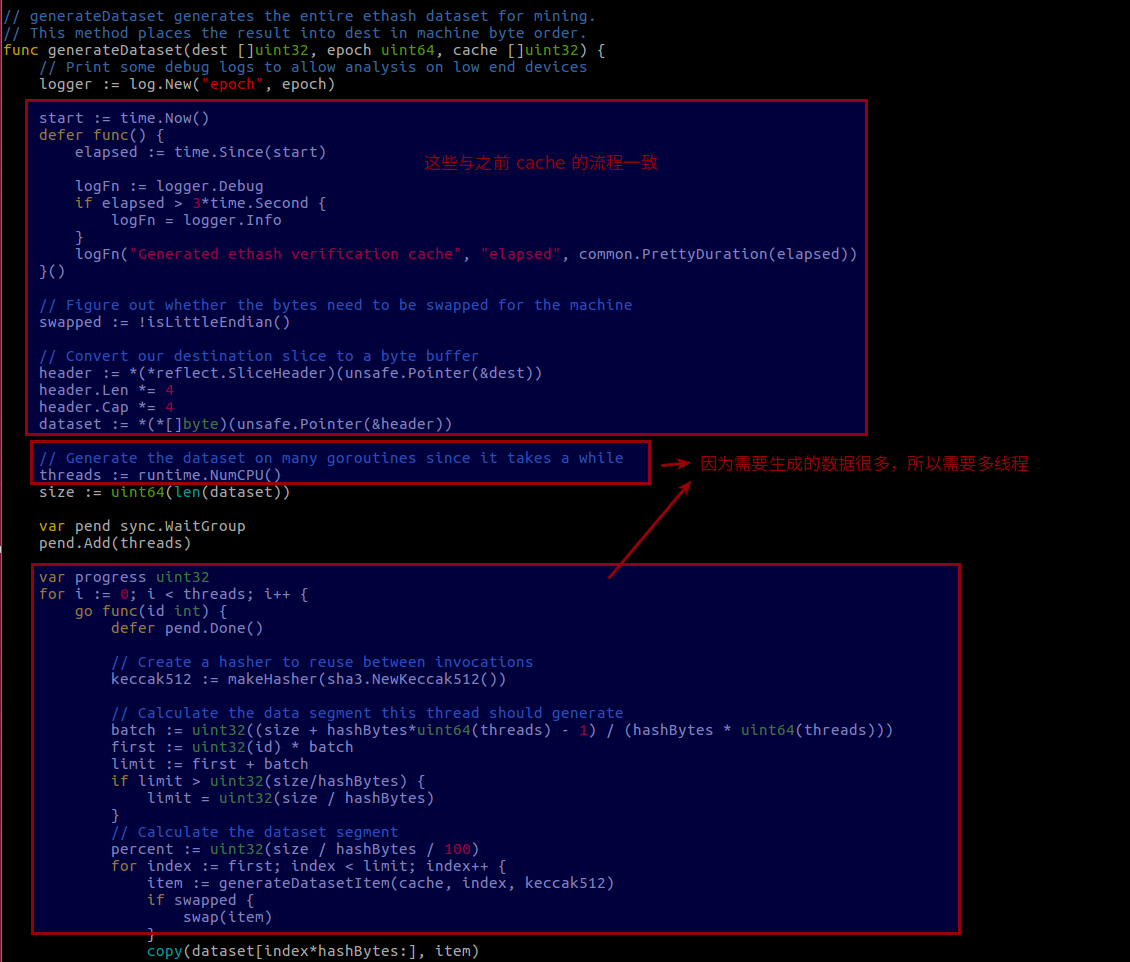
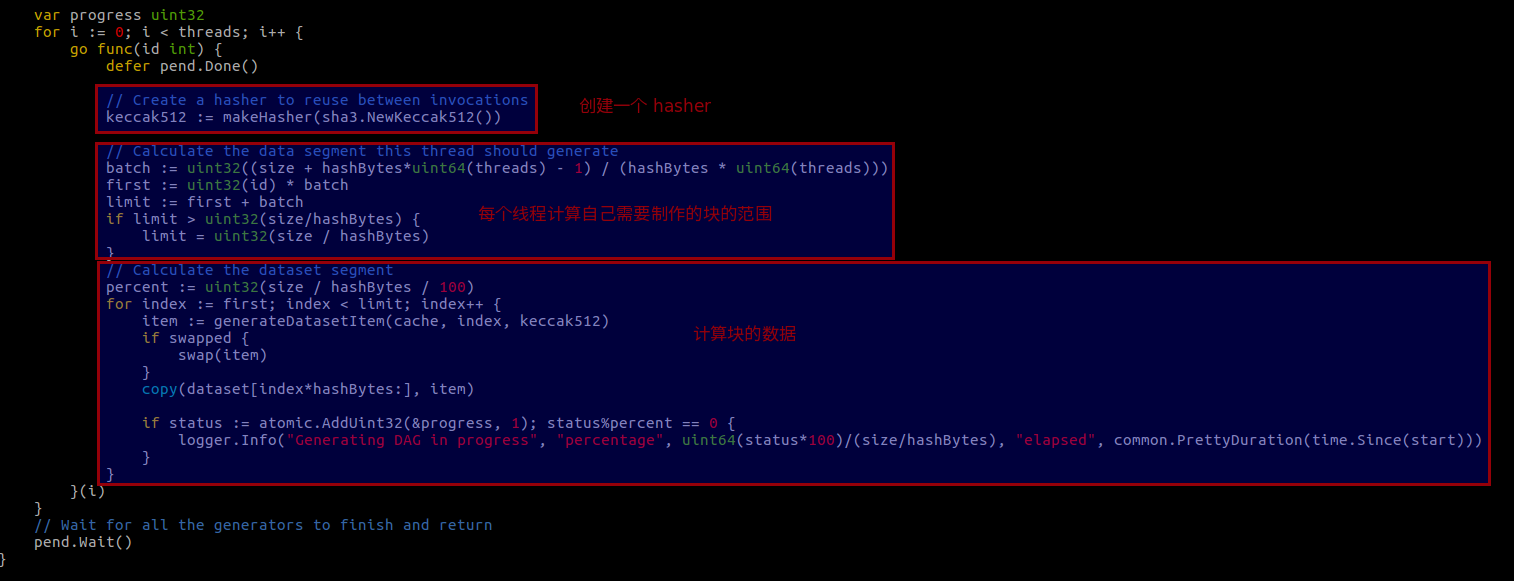
到这生成 cache 和 DAG 的流程就都介绍完了。
4. ethash 解决了什么问题
我们再回忆下之前说的共识算法要解决的三个问题:
- 抵制矿机(ASIC)。
- 全链数据存储。前面说的矿池的例子。
- 轻客户端。前面说的手机的例子。
之前的 hashimoto 解决了,1 和 2,但是因为需要全链数据,所以 3 没解决。
ethash,使用了类似 hashimoto 的算法,在保证 1 的基础上,因为 DAG 要比全链数据小很多,所以理论上可以应用在轻客户端上,3 算是解决了,那么 2 呢?首先肯定不是全链数据了,而且从 ETH 的代码里看,默认支持远程挖矿,也就是矿池模式,所以 2 是没解决的,或者说是以太坊不想解决的。
那么实际上中心化问题还是有的,但是因为解决了 1 和 3,使普通人可以挖矿,挖矿的整体人群扩大了,所以综合来看,个人觉得还是解决了部分的中心化问题。
参考
https://www.cnblogs.com/Evsward/p/ethash.html
https://github.com/ZtesoftCS/go-ethereum-code-analysis/blob/master/hashimoto.md
https://blog.msiter.com/Hashimoto%20IO%20bound%20proof%20of%20work-20180824.html
https://github.com/ethereum/wiki/wiki/Mining#so-what-is-mining-anyway