
之前对比特币和以太坊已经有一些了解,这次重新再看一遍白皮书,主要记录一些以前忽略或者理解不是很深的知识。
本人知识有限,如有错误和疏漏,请务必指正,多谢。
比特币白皮书
1. 默克尔树
默克尔树除了比特币、以太坊上的应用,在其他大多数的 P2P 分布式应用中都可见身影,其核心就是将大量数据进行 hash 后增加其分布式索引性能,通过维持一个较小的高效索引进而管理复杂的大量数据(引用自(大鱼)区块链和MerkleTree)。(在 android 校验镜像上也有应用,主要是用的默克尔树的另一个优势,快速重哈希)
在 P2P 的场景里(也包括比特币和以太坊等),获取整体数据一般都是从很多个节点获取,这样是为了缓解单个节点压力,也是为了提高获取速度。也是由于这个原因,从每个节点只获取整体数据中的一小块,这样就需要校验数据正确性,因为不是整体数据,所有没法知道整体数据的 hash 值(比如 md5),得想办法单独校验这一小块数据,所以就用到了默克尔树。
默克尔树是将一个区块里的所有交易记录,单独 hash, 然后两两 hash 结合再次 hash,依次类推,最后得到一个 Root Hash,看下面的左边的图:
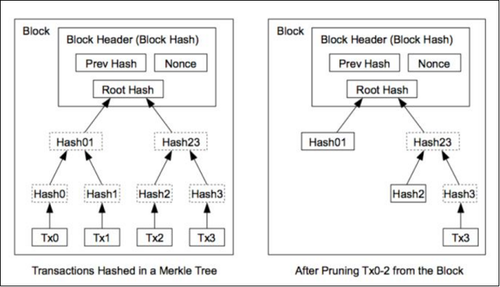
如果我是接收者的话,我只需要知道 Root Hash 就可以了,然后我就可以通过 P2P 从任意节点获取任意我需要的交易记录,并且可以验证交易记录的正确性,这是怎么做到的呢?
如上面的右边的图所示,比如我想获取 Tx3 这个交易记录,那么节点需要给我回传这些信息: Tx3、Hash2、Hash01。然后我自行计算 Hash3(也就是 Tx3 的 hash),然后与 Hash2 一起计算出 Hash23,然后与 Hash01 一起计算出 Root Hash,最后将这个计算出的 Root Hash 与我事先知道的 Root Hash 对比,如果一致,那么就说明传过来的 Tx3 是正确的。
这里有一个问题,如果所有传递过来的 Tx3 和 Hash等都是伪造的,且让这些伪造的数据按照上面的流程,计算出跟实际的 Root Hash 一致的结果,不就可以欺骗别人了么?
这样确实可以,但是这样做非常的难,因为这样相当于从 Hash 推导出可以求出这个 Hash 的原文,这是非常难的,哪怕量子计算时代到来。
所以运用默克尔树,可以在轻节点(比如钱包节点)上只保留区块的头部信息,在需要验证交易记录的时候,从其他节点获取少量的过程 Hash 即可,这样使钱包的体积非常小,才使在手机上运行成为了可能(包含完整块数据的全节点,现在需要 200 多 G 存储空间)。
而且区块头只有大概 80 字节,按照每十分钟生成一个区块的速度,所有区块头的体积每年只会增加 4.2 M,这些数据甚至可以全部装到内存里。
以太坊白皮书
1. 比特币相关
从技术角度讲,比特币账本可以被认为是一个状态转换系统,该系统包括所有现存的比特币所有权状态和“状态转换函数”。状态转换函数以当前状态和交易为输入,输出新的状态。例如,在标准的银行系统中,状态就是一个资产负债表,一个从A账户向B账户转账X美元的请求是一笔交易,状态转换函数将从A账户中减去X美元,向B账户增加X美元。如果A账户的余额小于X美元,状态转换函数就会返回错误提示。 比特币系统的“状态”是所有已经被挖出的、没有花费的比特币的集合。每个UTXO都有一个面值和所有者(由20个字节的本质上是密码学公钥的地址所定义)。(引用自以太坊白皮书)
状态转换系统,我觉得这个词很贴切,因为确实是如这样,不像是普通的货币一样,本身不记名,在谁的手中,就是谁的,比特币不是这样,比特币始终位于区块链上,只不过所有者信息一直在变(可以看这篇比特币-脚本相关)。
比特币的一些应用。利用比特币 first-to-file 原则实现的域名币系统,发行自己的数字货币的彩色币系统,创建新的协议的元币系统。
比特币是可以实现一定程度的智能合约的,比特币的 wiki 上有一篇专门介绍这个,以后争取写一篇相关介绍文章。
比特币的一些限制和缺点。缺少图灵完备性,价值盲,缺少状态,区块链盲。
2. 以太坊开始
- 以太坊一个很重要的概念是账户,账户分两种,外部账户和合约账户,账户包含四个部分
- 随机数,用于确定每笔交易只能被处理一次的计数器
- 账户目前的以太币余额
- 账户的合约代码,如果有的话
- 账户的存储(默认为空)
- 以太坊的消息在某种程度上类似于比特币的交易,但是两者之间存在三点重要的不同。
- 以太坊的消息可以由外部实体或者合约创建,然而比特币的交易只能从外部创建。
- 以太坊消息可以选择包含数据。
- 如果以太坊消息的接受者是合约账户,可以选择进行回应,这意味着以太坊消息也包含函数概念。
幽灵协议(“Greedy Heaviest Observed Subtree” (GHOST) protocol)
如果矿工A挖出了一个区块然后矿工B碰巧在A的区块扩散至B之前挖出了另外一个区块,矿工B的区块就会作废,这样会白白浪费掉算力,且没有对网络安全做出贡献。
从另一个方面讲,如果A是一个拥有全网30%算力的矿池而B拥有10%的算力,A将面临70%的时间都在产生作废区块的风险而B在90%的时间里都在产生作废区块。因此,如果作废率高,A将简单地因为更高的算力份额而更有效率,区块产生速度快的块链很可能导致一个矿池拥有实际上能够控制挖矿过程的算力份额。
由于这两个原因,幽灵协议提出了“叔区块”的概念,以叔区块为新块确认做出贡献的废区块也会得到 87.5% 的奖励,“侄区块”会获得 12.5% 的奖励,最多下探到第五层。
以太币是持续发币的,每年有 0.26 × 发售总量的币被挖出。注意这里是发售总量,不是发行总量,发售总量是以太币最开始发售的数量。因此从长期来看,货币供应增长率是趋于零的。另外由于有丢失或者死亡等原因,币的遗失和增发最终来看会达到一个平衡。 其实比特币也虽然发行总量是固定的,但是也不一定会导致通货紧缩,所以这里我觉得都可以
比特币的一个问题是越来越中心化,这个从两个方面来看,一是由于矿池的出现,大部分连接矿池的电脑没有完整的区块链数据,是依靠矿池来提供验证,所以其实是矿池控制了所有的矿机,计算力很集中,二是比特币完整区块链现在已经 200 多G,还在以每年大概 50 G的速度增长,这样会导致,对矿机的硬盘容量要求越来越高,慢慢只有大型组织才能负担的起这样庞大的硬件消耗,计算力只会越来越集中。
以太坊有这方面的措施,首先以太坊会通过挖矿算法迫使每个矿工成为一个全节点,其次全节点无需存储完整的区块链历史,只需要存储状态。
MPT 不同于比特币的默克尔树,以太坊使用 MPT(Merkle-PatricaTrie) 来存储核心数据的校验数据。
以太坊一共使用了三个 MPT 对象,state Trie、tx Trie、receipt Trie,分别对应账户状态、交易状态、收据状态。
上个点说的以太坊用来解决存储数据越来越大的方法,其中一个是只存储状态,就是指的这三个状态,但是需要注意的是,这些状态只能用来校验数据是否正确,但是并不是数据本身,也就是说,如果全节点上只有这些状态,那么他还是需要从别的包含完整数据的全节点获取数据,才能进行交易的验证。这种只包含状态的全节点,应该算是比特币的全节点和轻节点的中间状态。
一些感想
比特币虽然引入了区块链和比特币本身,但是核心还是比特币本身,虽然比特币也支持有限的合约,也有一些诸如染色币、域名币、元币的应用,但是这些应用其实都脱离开了比特币本身,要么需要特殊客户端,要么就是一条新链或新协议。
以太坊是作为应用平台出现的,原生就可以支持应用的开发,而且功能完善,这是以太坊的很大优势。 以太坊属于比特币的升级版本,并不能算是完整的创新,很多理念还是来源于比特币,虽然在很多方面有优化,比如尝试解决算力集中问题,存储空间大的问题等。不过并不能算是真正解决了这些问题,只能说是优化。
我觉得现在无论是比特币还是以太坊,下面这些问题都还是核心问题,如果不能妥善解决,还是会影响到以后的发展:
- 算力越来越集中
- 存储空间越来越大
- 性能低下
这样来看,对于联盟链来说,只有存储空间的问题,或许目前来看联盟链是个更好的发展方向。