
前一阵子看完了 YOLO 的 1-3 论文(YOLO1-3学习总结),也用官方提供的 weights 跑了下,效果确实不错。
这段时间一直在合计自己训练个模型,最后选择了微信的跳一跳。
为什么选跳一跳呢,因为它简单,用来学习模型再好不过。跳一跳里方块的种类比较少,样子也变化不大,这样标记和训练起来都可以节省很多时间。
记得跳一跳刚出来的时候,同事就弄了一个辅助工具来玩,当时跳了800多分,很是惊讶,这也行!现在上网查查,很多辅助工具已经可以跳到2万分以上,我真是拜了。
但是下载代码看,都不是使用的深度学习,一般是直接分析图片像素(因为跳一跳简单)或者使用 opencv,所以能借鉴的地方不多。
没做之前,我给自己定的目标是1000分就行了,并不奢望能达到上万分,毕竟实现方式不同,后来实际的结果虽然确实没有做到上万分,但是已经远超1000分。
下面就一步步介绍下自己的整个实践过程,最后会附上代码和训练集的下载地址。
获取数据
数据需要是游戏截图,但是边玩边截图,有点麻烦,所以我是先录像,然后在从录像里面截取图片。
手机录像工具有很多,我使用的是“录屏精灵”,免费是标清 1280 * 720,还可以,唯一的问题是录时间长了,自己莫名奇妙就退出了,害我白录了很多次。
为了提高训练的效果,录像要尽量覆盖高分和低分的场景,因为高分的时候,有些方块更小,互相之间的距离也不一样,这些场景尽量在训练集中都要出现。
但是前期手打还是比较难的,我是最多只打到了100多分(见笑),所以我的训练集中,大部分的数据是集中在0-150之间的,不过这样也没关系,在训练出模型之后,模型要比你打得好多了,很容易就打上高分,出现识别有问题的情况的时候,再手动截图,增加到训练集即可。当然,你也可以下载一个别人的辅助工具来玩,然后录像。
从录像中截取图片这里,我写了工具,仓库地址,tiao_tools/video_to_image.py。
1
2
3
4
5
6
7
8
PRE_FRAME_KEY = 44 # ',',前一帧
NEXT_FRAME_KEY = 46 # '.',后一帧
PAUSE_KEY = 32 # ' ',暂停
SAVE_IMG_KEY = 47 # '/',保存图片
EXIT_KEY = 27 # 'esc',离开
save_image_path = os.path.abspath('./') + '/img/' # 保存图片地址
video = '/home/cooli7wa/project/pycharm/tiaotiao/video/20180617123132.mp4' # 录像地址
设置好保存图片和录像的地址,然后运行工具就可以,到想要截图的时候,“空格” 暂停,然后 “,” 或 “.”,向前或向后微调帧,按 “/” 来保存当前图片。
我是最开始选择了大概500张图片,后续陆续增加到了550多张。
标记图片
标记图片的工具很多,我使用的是 labelImg,支持 windows、linux 和 macOS。
工具很不错,使用起来很方便,尤其是会显示当前鼠标位置的横竖轴线。
使用之前,需要更改下 data/predefined_classes.txt,改成你自己的类别名,更改好的 仓库地址
对于跳一跳来说,没必要给每个不同的方块都分一个类,我只分了3个类,分别为 chessman、box_score 和 box_normal,chessman 是黑色的小人,box_score 代表是可以额外得分的方块,box_normal 是普通的方块。其实后来发现,box_score 也是没什么用的,因为受限于很多方面的因素,跳的速度没法很快,在方块上等待的时间,基本都超过了额外得分需要等待的时间。所以,这里分两个类也是可以的,标记起来会更快。
对于标记图片,有一些需要注意的地方:
- 标记方块的上表面即可。距离依据上表面的中心计算的。
- 小人我是标记的整个人,虽然有用的只是底面中心,但是这个比较好计算,只要将小人方框的最下边框的中心位置,上移一点,即是小人的底面中心。
- 标记的框,最好紧贴物体的边缘。不要画很大的一个框,离实际边缘很远,也不要画到物体内部去。
- 标记的框,尤其不要左右或者上下间隙不同。
- 对于不完整的方块,比如少露出一个角,我的一般是看露出的比例,如果超过50%的画,就要标记上。当然这时候标记的框就不是正好在四个顶点上了。 这里多说一点,我最开始的时候,没有标记这种不完整的方块,因为我觉得游戏里不会出现需要跳到不完整的方块上这种情况,其实虽然不多,但是确实有,如果训练集里这种都没标注的画,模型遇到这种情况会找不到目标方块。
- 标记完所有的图片,最好多检测几次,不要出现漏标,或者标错的情况。
- 框标记的越完美,越符合统一的标准,训练的结果一般也就越好。
标记完的图片大概这个样子:
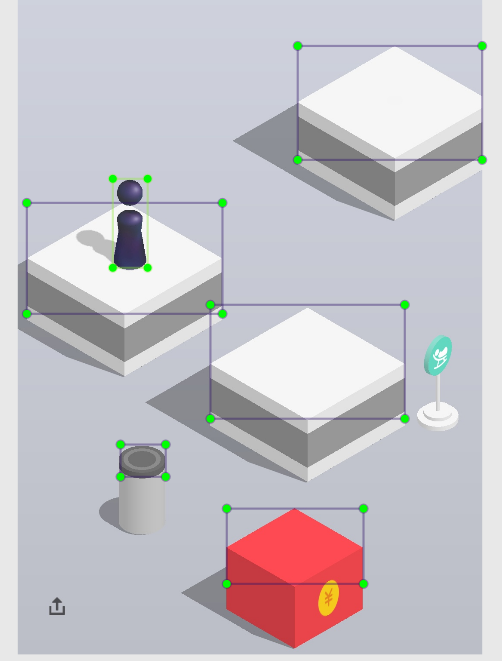
标记完的图片,会生成一个 xml 文件,记录的是标记的框的位置和分类信息。
训练前的准备工作
训练我是直接使用的官方的 darknet 框架。
将 xml 文件转换为 darknet 需要的文件,仓库地址,tiao_tools/voc_label_tiao.py 这个为了适配跳一跳,相对原版有一些改动
1 2
classes = ["box_normal", "box_score", "chessman"] # 自己的分类信息 prop = 1.0 # 这个是 train 和 test 的训练集的划分比例,训练模型,不需要 test 数据集,而且我们的数据比较少,所以这里我设置为了1,也就是全都划分为 train 数据。
1
python voc_label_tiao.py <image folder path>
运行之后,会给每个图片生成一个 txt 文件,并且生成一个 train.txt 文件,记录了所有图片的位置,后面训练会用到。
darknet 框架内有一些需要配置,更改好的仓库地址。下载后都得重新编译下,记得开启 GPU、CUDNN、OPENCV。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
// 新建 cfg/tiao.data,路径替换成自己的路径 classes= 3 train = /home/cooli7wa/project/pycharm/tiaotiao/img/train.txt valid = /home/cooli7wa/project/pycharm/tiaotiao/img/test.txt names = data/tiao.names backup = /home/cooli7wa/project/yolo/darknet_pjreddie/backup // 复制 cfg/yolov3-voc.cfg 为 cfg/yolov3-tiao.cfg,并更改如下内容 [net] # Testing # batch=1 训练时,注释掉 # subdivisions=1 训练时,注释掉 # Training batch=64 训练时,开启,如果提示oom(显存不够),可以改小点 subdivisions=16 训练时,开启,如果显存不够,可以改大点 ... learning_rate=0.001 burn_in=1000 #max_batches = 50200 这个是总的迭代次数,我们不用训练那么久,所以改小点 max_batches = 3000 policy=steps #steps=40000,45000 这个控制学习速率的衰减,也改小点 steps=2000,2500 scales=.1,.1 ... [convolutional] size=1 stride=1 pad=1 #filters=75 filters一共有3处,根据 anchor_num*(5+class_num)计算出来,我的是24 filters=24 activation=linear [yolo] mask = 0,1,2 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 #classes=20 这种classes一共有3处,我是3个类别,所以这里都改成3 classes=3 num=9 jitter=.3 ignore_thresh = .5 truth_thresh = 1 #random=1 这个是扩展数据集用的,对于跳一跳可以不用开,可以减少显存的使用 random=0 // 新建 data/tiao.names chressman box_store box_normal // 更改 examples/darknet.c,指向 cfg/tiao.data @@ -437,7 +437,7 @@ int main(int argc, char **argv) char *filename = (argc > 4) ? argv[4]: 0; char *outfile = find_char_arg(argc, argv, "-out", 0); int fullscreen = find_arg(argc, argv, "-fullscreen"); - test_detector("cfg/coco.data", argv[2], argv[3], filename, thresh, .5, outfile, fullscreen); + test_detector("cfg/tiao.data", argv[2], argv[3], filename, thresh, .5, outfile, fullscreen); } else if (0 == strcmp(argv[1], "cifar")){ run_cifar(argc, argv); } else if (0 == strcmp(argv[1], "go")){
训练
在 darnet 目录,执行下面这个命令
1
./darknet detector train cfg/tiao.data cfg/yolov3-tiao.cfg
如果你是增量训练,也就是有之前训练的 weights,那么可以使用下面这个命令(weights 名字替换下)
1
./darknet detector train cfg/tiao.data cfg/yolov3-tiao.cfg backup/yolov3-tiao.backup
如果你想保留训练过程中的输出到日志文件,可以这样
1
./darknet detector train cfg/tiao.data | tee train_log.txt
这样得到的 train_log.txt 里包含训练过程中的 loss 信息,可以用来绘制 iter-loss 图,仓库地址,tiao_tools/plot_curve.py
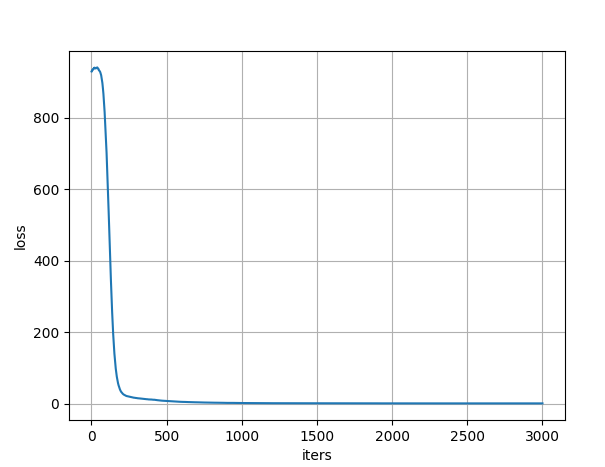
3000次的迭代,1060 和 i5-8300H 的笔记本,大概需要6个小时,最后 loss 在 0.5 左右,Avg IOU 在 80% - 90%,详细的看下图,这是最近一次训练,第3000次迭代的结果,作为参考吧。
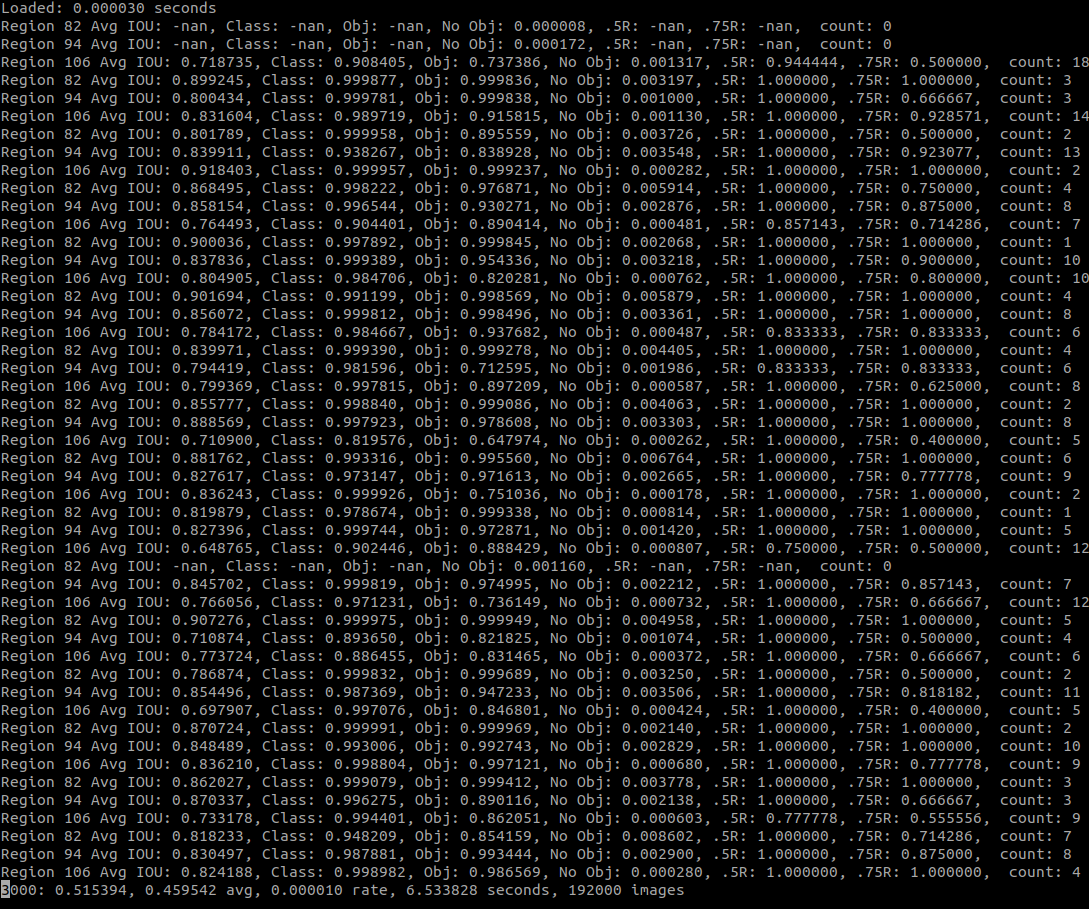
关于这个输出,有几点需要注意下:
nan,训练到10000次,nan 也一直存在,但是不影响实际使用,只要 nan 不出现在类似下面这种 loss 的输出里,就没关系,训练过程还是正常的。
1
3000: 0.515394, 0.459542 avg, 0.000010 rate, 6.533828 seconds, 192000 images
IOU,这个反应的是预测时候的框的准确度,我尝试过很多方式,这个值一直没有稳定在 90% 以上。
Class,是分类的准确度,因为我们类别很少,这个正确率很高
Obj,这个是识别出物体的概率,越高越好
No Obj,这个是没有物体的时候,识别出问题的概率,越低越好
.5R,这个是 50% IOU 的时候的召回率,越高越好
.75R,这个是 75% IOU 的时候的召回率,同样越高越好
训练中,在 backup 目录里,1000 次迭代以下时,每 100 次迭代,生成一个 weights 文件,1000 次以上时,每 100 次迭代,更新 yolov3-tiao.backup 文件。
全部 3000 次训练完,会生成 yolov3-tiao_final.weights 文件。
开始游戏
darknet 用来训练不错,速度很快,而且显存占用小,但是是用 c 写的,跳一跳游戏逻辑相关的代码,还是 python 写起来方便,所以这里使用的是 keras-yolo3 的框架,这个是 yolov3 的 python 实现。
keras-yolo3 提供工具可以将 darknet 训练出来的 weights 和 cfg 文件,转换成自己需要的 yolo.h5 文件。
仓库地址 convert.py
1
2
# 将 darknet 的 cfg 文件和训练出来的 weights, 复制到根目录,然后执行
python convert.py yolov3-tiao.cfg yolov3-tiao_final.weights model_data/yolo.h5
仓库的代码相对于原版,针对跳一跳进行了一些修改,并增加了 tiao.py,这个是主要的游戏代码。
1
2
3
4
5
6
7
8
9
WAIT_AFTER_JUMP = 3000 # 跳后等待的时间,主要是等待游戏中下一个方块,落平稳
CAPTURE_FOLDER = '/home/cooli7wa/Desktop/tmp_image/' # 保存临时图片的位置
CAPTURE_FILE = CAPTURE_FOLDER + 'screen.png' # 截屏的保存路径
IMG_PATH = '/home/cooli7wa/project/pycharm/tiaotiao/img/' # 遇到无法识别的物体,自动保存图片的路径
PRESS_PARAM = 1.375 # 按压时间参数,距离×此参数=按压时间
CHESS_CENTER_CORRECT = 22 # 小黑人底线到底部中心的修正距离
INVALID_BOX_DISTANCE = 20 # 无效的目标方块的判定范围
RESTORE_NUM = 50 # 临时保存图片的数量
RESTART_GAME_POS = [600, 1700] # 重新开始按键的位置,这个根据手机的分辨率设置下
主要流程如下:
- 通过 adb 命令截屏手机,并将截图下载到本地
- 调用 yolo 来识别图片中的物体,找到小黑人和目标方块的中心位置
- 计算中心位置的距离,并转换为按压时间
- 通过 adb 命令按压手机屏幕来控制小人跳跃
- 等待下一个方块落稳,回到步骤1
如果无法识别到目标方块或者小黑人或死掉了,那么会自动保存当前截图到指定目录,然后重新开始游戏。
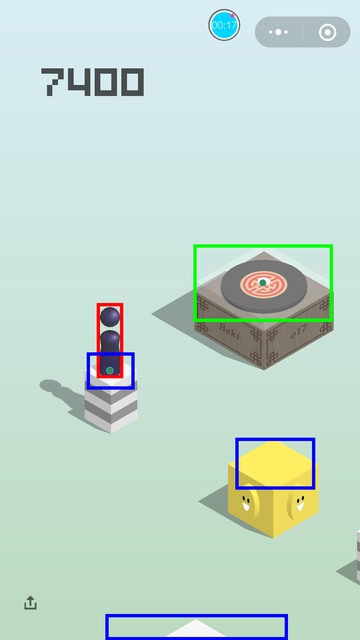
一些效果图:
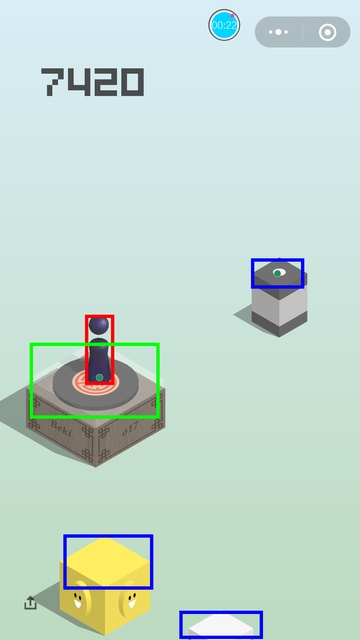
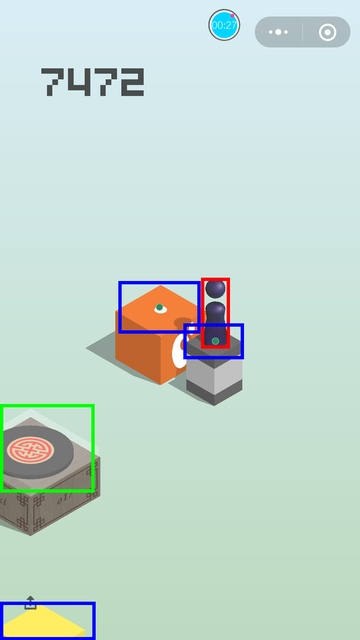
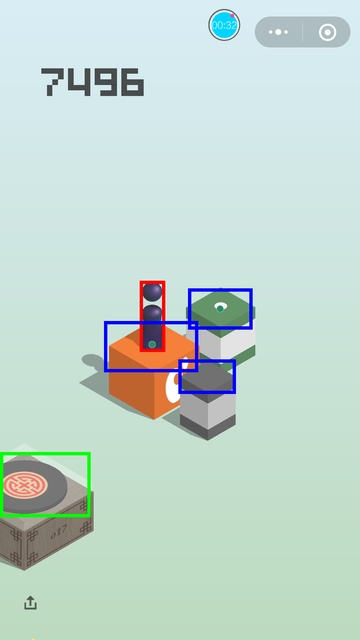
关于成绩
这套代码最高打到过 9000 多分,死掉的原因都是因为方块的识别位置有些偏差,从上面的图像就可以看出来,这个导致了中心距离算得不够准,在遇到距离很远,方块又很小的时候,就有可能会掉下来。
我尝试过哪些方式改进:
增加迭代。曾经迭代到10000次,也没什么效果
修改 cfg 使用更密的 grid。一般更密的网格,在识别很小的物体的时候,有效果,但是在这里,没什么效果。
可以用这个工具来画上网格看看,tiao_tools/draw_grid.py,就会发现其实现在的13、26、52已经很密了。
使用更小的学习速率。这个是有效果的,尤其是到迭代后期的时候,loss 基本维持在很低的水平,一个更小的学习速率,可以使 loss 更低一些。
重新制作 anchor box。很多人推荐这个,我使用 k-means 聚类算法将所有标记的框分为了9类,然后像 yolo 的做法一样,从小到大排序分为了3组,重新训练整个模型,但是没有什么效果。
增大输入图片的尺寸。从 416×416 修改为 608*608,没什么效果。
检查图片的标记。这个最后说,是因为这个是最有用的,标记位置不准的问题,很大的原因是因为训练用例的标记没有很完美,有漏标记、错标记或者标记偏的情况。如果可以再仔细检查下所有的标记,并且耐心调整标记的位置,那么成绩应该可以再高很多。
上面说的这些,一些没什么效果,但是很可能并不是这个方法有问题,而是对于跳一跳来说没什么效果而已。
这个游戏,因为图像简单,我觉得影响最大的还是训练集的标记准确度。
另外提醒一点,现在这种打出来的分数,微信都给屏蔽掉了,是提交不到服务器的,就当学习或者自娱自乐吧。
代码和数据地址
文中出现的和这里列出的都是基于原版修改过的代码,感谢原作者。
- git@github.com:cooli7wa/keras-yolo3.git
- git@github.com:cooli7wa/labelImg.git
- git@github.com:cooli7wa/darknet.git
数据地址:
- weights、cfg、train_log:https://pan.baidu.com/s/1wl7Dmc_IUWin363z6Dqr7g
- 带标记的训练集:https://pan.baidu.com/s/1lgTwV6t-MWo2DutK0B28Tw
最后附上一段游戏视频,祝大家开心。