
Why are deep neural networks hard to train?
前一章有介绍,任意函数都可以通过2层神经网络来求解,但是并不是说任何问题都用两层就好了。因为“可以做到”并不一定是“最好的”。
作者的观点是,当使用2层神经网络来解决问题的时候,需要的神经元的数量可能是多层网络的指数倍,设计的困难程度也比多层复杂得多。
Deep circuits thus can be intrinsically much more powerful than shallow circuits.
如果我们都用深层网络呢?做之前的手写识别(之前是2层),会不会提升很多?作者实验的是不会,甚至没有提升。
原因是前层和后层,总有在stick的,没有真正在学习,学习速率差距很大。
后面作者会阐述问题原因(本章)和解决办法(下一章)。
The vanishing gradient problem
- vanishing gradient problem 当增加层数(每层都是30神经元)的时候,准确率有时还会下降 这里有问题,因为按照常理来说,哪怕新增的层,没有什么可以学习的了,那么也就是什么都不做,也至少应该和原来的准确率一致,但是现象确实有时会下降。
作者使用\(\frac{\partial C}{\partial b}\)来指示梯度情况,这个实际上是\(\delta\),因为实际上w的偏导,也与\(\delta\)有关,不过是多了一个a,所以这个来衡量梯度情况是可行的。
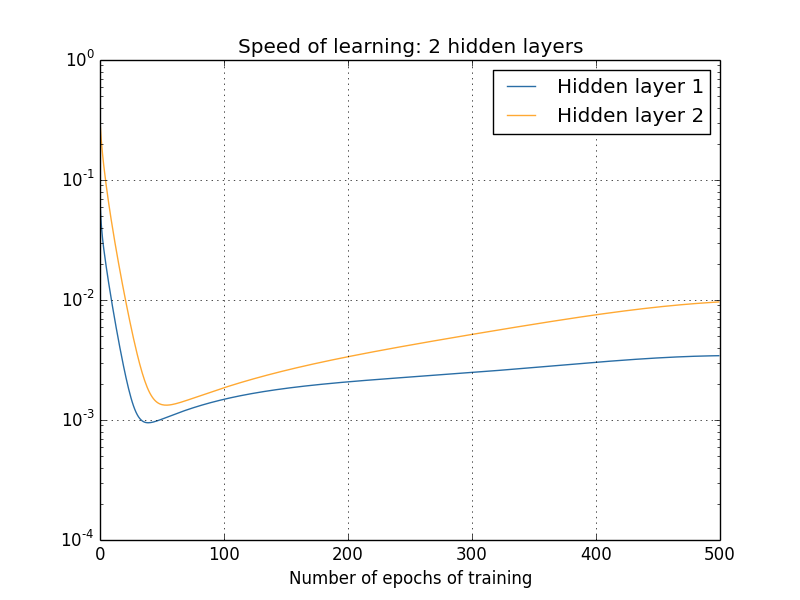
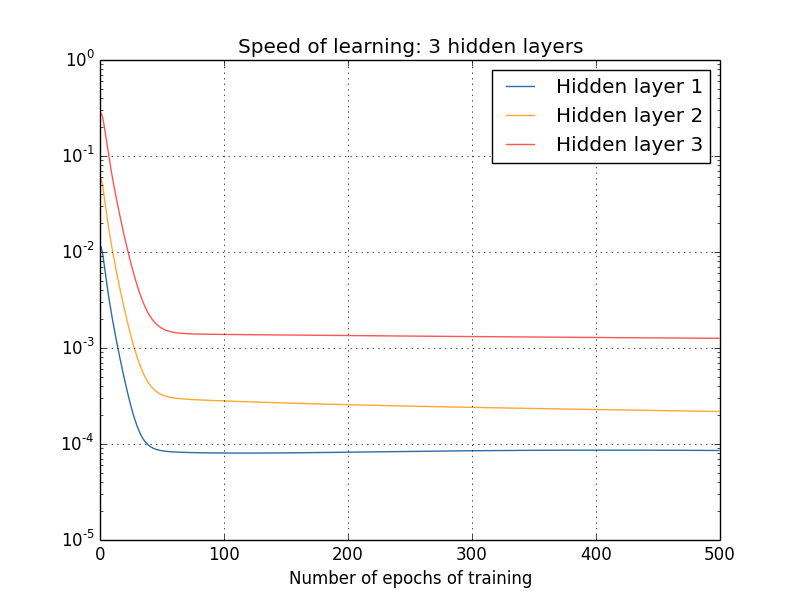
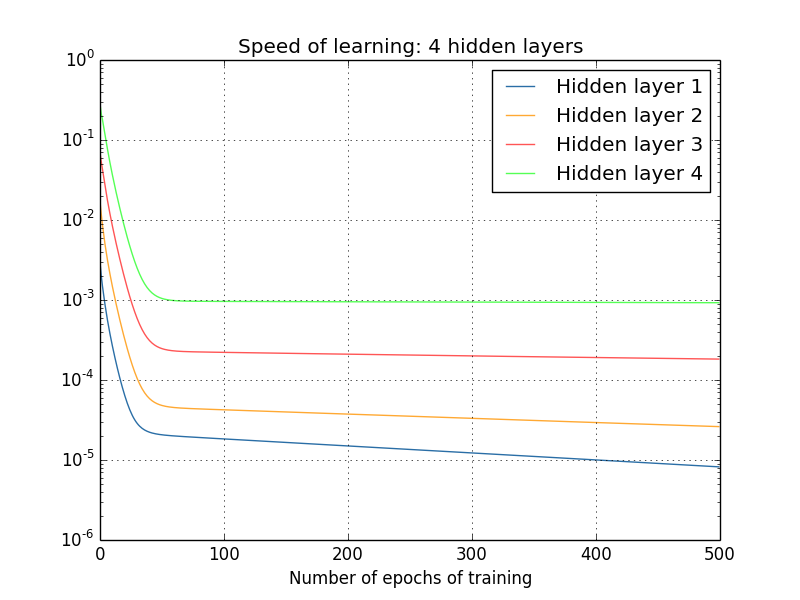
可以看出来,越前面的层,梯度越小,这个就是梯度消失问题
首先需要确定是这个梯度消失问题,是不是个问题?因为从导数来看,导数越小,说明越接近正确值,这样不是更好?
其实不是,因为这里面的图片都是刚开始训练时候的数据,而最开始的参数都是随机取的,而随机取的参数基本不会是合适的参数,所以前面的层来说,不合适的参数会导致,图像得很多特征没有被正确获取到,如果梯度很小,训练很慢得话,那么肯定是有问题的。
- exploding gradient problem 这种是梯度爆炸,就是与上面的对立的情况,前面层的梯度特别大,后面的反而很小 作者暂时没有细说
What’s causing the vanishing gradient problem? Unstable gradients in deep neural nets

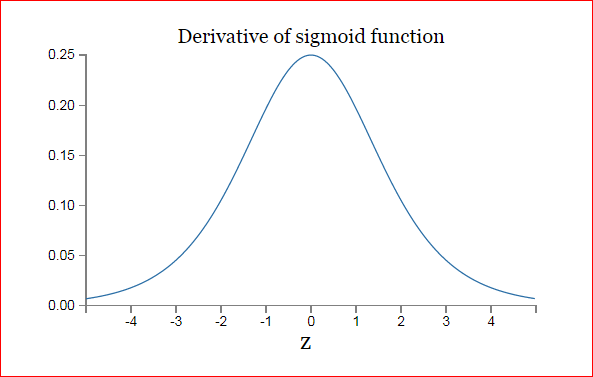
由于我们使用的是标准正态分布的方式初始化变量,所以一般情况下(68.2%), |w|<1,σ′(z)<1/4,所以|wjσ′(zj)|<1/4
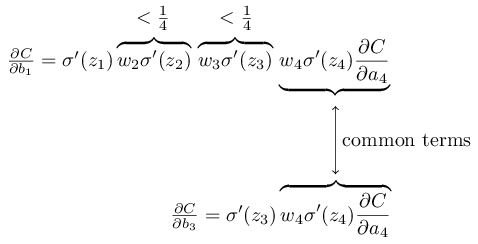
所以这就是梯度消失的原因。
如果这里的不是<1/4,而是远大于1,那么就是梯度爆炸了
这两都是梯度不稳定,The unstable gradient problem,所有层的学习速率有着很大的不同。
这里是用的一种很简答的模型(只有一个神经元每层),对于正常的模型,也是类似的情况。
要知道一点,这个问题,作者是用sigmoid做例子,但是不只是sigmoid有这种问题 sigmoid是比较倾向于出现梯度消失的问题,而其他的激活函数,可能有别的问题
Other obstacles to deep learning
除了梯度问题,还有其他的问题,其中一个是关于sigmoid的
In particular, they found evidence that the use of sigmoids will cause the activations in the final hidden layer to saturate near 0 early in training
还有其他的,不详细记录了