
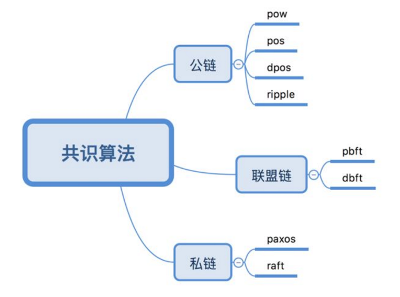
区块链也是一种分布式系统,很多传统分布式系统上的共识机制在区块链上也有使用,比如 paxos、raft、pbft 等,一般应用在联盟链和私链上。而公链的算法主要是 PoW、PoS、DPoS、RPCA 等。这里有张图,不是很全,有个直观的印象:
这篇文章主要是想总结下 PBFT、RAFT 相关的知识。其实这几个算法之前就看过了,但是一直没有来总结,主要是觉得涉及的东西很多,自己并不算充分了解,只是如果迟迟不总结,又觉得知识很松散,不便于记忆和补漏,所以还是先写一篇,总结下目前自己对这些算法的认识,以后再不断更新。所以如果哪里有问题,欢迎指出。
预计总结下面这些内容:
CFT (Crash Fault Tolerance) 与 BFT (Byzantine Fault Tolerance)
- RAFT (Replicated And Fault Tolerant),属于 CFT
- 两将军问题
- BFT (Byzantine Fault Tolerance) ,属于 BFT
- PBFT (Practical Byzantine Fault Tolerance),属于 BFT
CFT (Crash Fault Tolerance) 与 BFT (Byzantine Fault Tolerance)
先说这个,是因为可能很多人并不熟悉之间的区别(我以前也是),知道这个有助于理解算法的使用范围。
根据要解决的问题是普通错误还是拜占庭将军问题,共识算法可分为 CFT 和 BFT。普通错误是指,节点不会作恶,错误一般是故障,比如掉线、死机等引起;拜占庭问题是指,节点可能因为贪图利益而故意伪造信息、拦截信息等。
CFT 的一些经典算法有 Paxos、RAFT 等;而 BFT 的算法分为两类,确定性和概率性,确定性算法比如 PBFT,而概率性算法有 PoW、PoS等,确定性算法一般用在联盟链,概率性的一般用在公链上。
RAFT (Replicated And Fault Tolerant)
RAFT 是 CFT 的一种,即节点只会故障不会作恶。
RAFT 中的每个节点有三种角色,跟随者(follower),候选人(candidate),领导者(leader),集群中的每个节点在某一时刻只能是这三种角色的其中一种,角色会随着时间和条件的变化而互相转换。
RAFT 算法主要有两个过程:一个是领导者选举,另一个是日志复制。领导者选举发生在无法与旧的领导者通信的情况下,多个跟随者会将自己转换为候选人,然后进行选举,只有一个候选人可以选举成功,一旦成功,自己就成为了新的领导者;而日志复制过程分为记录日志和提交数据两个阶段。
RAFT 算法支持最大的容错故障节点数是 \((N-1)/2\),其中 N 为集群中的总的节点数量。
这里有一个很不错的 RAFT 动画,介绍了选举、日志复制、网络分区(脑裂)等情况,可以看看。
两将军问题
两军问题是计算机领域的一个思想实验,用来阐述在一个不可靠的通信链路上试图通过通信以达成一致是存在缺陷的和困难的,这个问题和更有名的“拜占庭将军问题”有关。两军问题是在计算机通信领域首个被证明无解的问题,由此也可以推论出,在随机通信失败的条件下“拜占庭将军问题”也同样无解。
这里的随机通信失败(不可靠通信链路),是指通信可能丢失或者无限期延迟,但一般假设消息本身不会被篡改。
下面是一个简化的例子,将军甲和将军乙打算一起进攻敌军,但是甲乙间的通信线路必须经过敌军阵营,所以就可能信使被杀导致通信失败。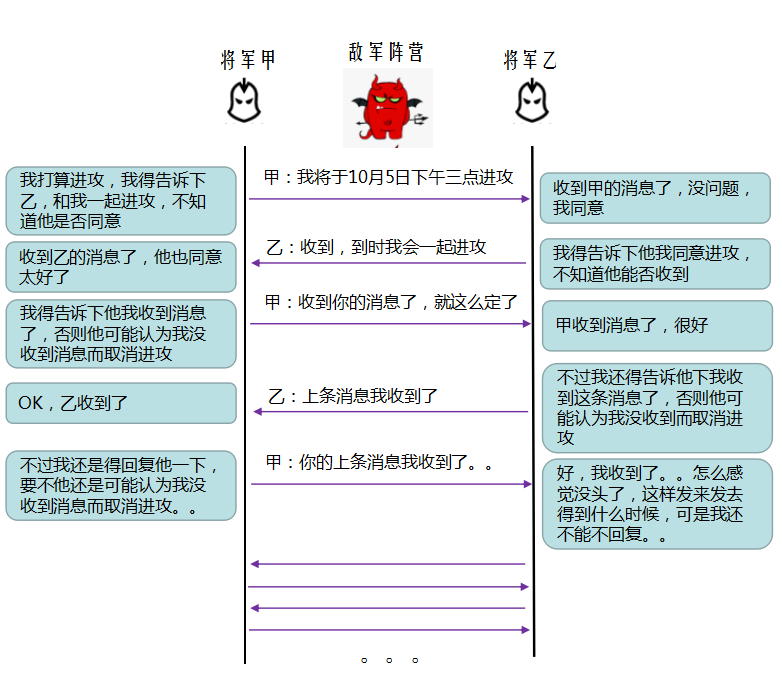
可以看出来,由于通信的不可靠,无论哪方将军发送一条消息之后都渴望得到反馈来确认消息被接收了,同时又想回复一条消息给对方,告诉对方他的消息已经被收到了,这就导致了几乎不可能达成共识。
设想如果通信可靠,一方发送完消息后,知道消息一定会被对方在有限时间内收到,就不用渴望反馈了。
是不是觉得这个问题基本无解了?
其实也不是,对于工程来说,虽然通信无法做到 100% 可靠,但是可以通过多次发送同一个消息,来保证这些消息有很大的概率被至少接收到一次,从而降低了不可靠的程度,而一方只要接收到至少一次消息,就按照消息执行,那么共识也是可以达成的。
BFT (Byzantine Fault Tolerance)
这里该介绍 BFT 了,也就是拜占庭容错。前面的两将军问题不算是 BFT,因为并没有什么作恶节点,主要是不可靠通信导致的问题。那么为什么要先说两将军问题呢?主要是两将军问题引出了一个很重要的常识:在通信不可靠的情况下,试图通过通信达成一致是不可能的或者是十分困难的,这同样适用于 BFT,所以这里讨论的 BFT 的前提是:信道可靠,也就是在有限的时间内,消息一定可以到达,而且消息本身无法被更改。
BFT 算法支持最大的容错故障节点数是 \((N-1)/3\),其中 N 为集群中的总的节点数量。BFT 算法复杂度是 \(O(n^{f+1})\)。
至于容错故障节点的数量和复杂度是怎么得出的,这里先截取一段来源于网上的解释:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
例如,N = 3,F = 1 时。
若提案人不是叛变者,提案人发送一个提案出来,收到的叛变者可以宣称收到的是相反的命令。则对于第三个人
(忠诚者)会收到两个相反的消息,无法判断谁是叛变者,则系统无法达到一致。
若提案人是叛变者,发送两个相反的提案分别给另外两人,另外两人都收到两个相反的消息,无法判断究竟谁是
叛变者,则系统无法达到一致。
更一般的,当提案人不是叛变者,提案人提出提案信息 1,则对于合作者来看,系统中会有 N - F 份确定的信
息 1,和 F 份不确定的信息(可能为 0 或 1,假设叛变者会尽量干扰一致的达成),N − F > F,即 N > 2F
情况下才能达成一致。
当提案人是叛变者,会尽量发送相反的提案给 N - F 个合作者,从收到 1 的合作者看来,系统中会存在
(N - F)/2 个信息 1,以及 (N - F)/2 个信息 0;从收到 0 的合作者看来,系统中会存在 (N - F)/2
个信息 0,以及 (N - F)/2 个信息 1;
另外存在 F − 1 个不确定的信息。合作者要想达成一致,必须进一步的对所获得的消息进行判定,询问其他人
某个被怀疑对象的消息值,并通过取多数来作为被怀疑者的信息值。这个过程可以进一步递归下去。
Leslie Lamport 等人在论文《Reaching agreement in the presence of faults》中证明,当叛变者
不超过 1/3 时,存在有效的拜占庭容错算法(最坏需要 F+1 轮交互)。反之,如果叛变者过多,超过 1/3,
则无法保证一定能达到一致结果。
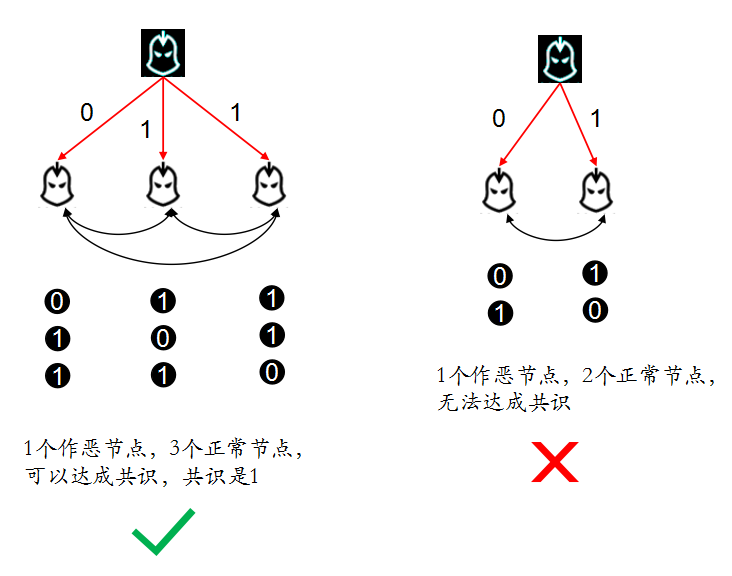
下面是几张图,解释下上面的文字。位于上方的提案人,下方的是接收者。
第一种情况,提案人是叛变者,会给不同的接收者发送不同的消息:
第二种情况,接受者是叛变者,会给其他的接收者发送不同的消息:
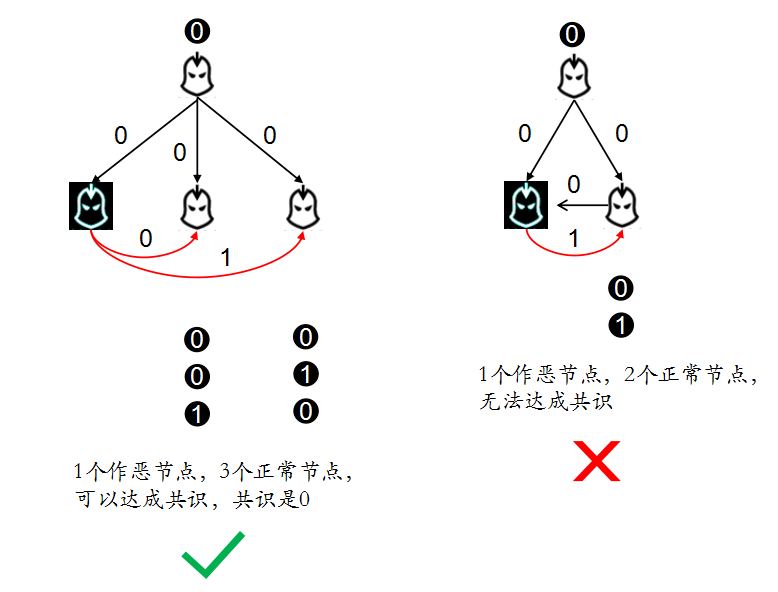
这是 3 个和 4 个节点的情况,我们知道了再有 1 个节点作恶的情况下,必须要有 3 个正常节点才能达成共识。那么如果节点数很多的情况怎么办呢?比如 9 个节点,其中 3 个作恶节点,能不能达成共识呢?是不能的,可以这么理解,将 9 个节点 3 个分为一组,那么可以得到 3 组,一组都是作恶节点,两组是正常节点,那么这种情况就和 3 个节点的情况一致了,是无法达成共识的,所以最大的容错故障节点数是 \((N-1)/3\)。
这里有一个视频,讲了两将军问题和BFT(需要翻墙),很不错,可以看看。
PBFT (Practical Byzantine Fault Tolerance)
终于到 PBFT 了,PBFT 主要是将 BFT 的算法负责度从指数级降到了多项式级,即 \(O(n^2)\)。
PBFT 算法支持最大的容错故障节点数也是 \((N-1)/3\),这个跟 BFT 一致。
PBFT 算法的理解,其实也可以参考上面的图,将提案人换成主节点即可。
这里主要说下算法的基本流程,主要有四步:
- 客户端发送请求给主节点
- 主节点广播请求给其它节点,节点执行 pbft 算法的三阶段共识流程。
- 节点处理完三阶段流程后,返回消息给客户端。
- 客户端收到来自 f+1 个节点的相同消息后,代表共识已经正确完成。
其中三阶段的流程如下图:
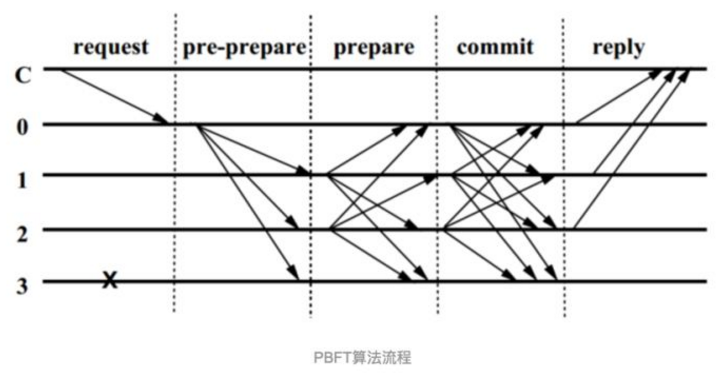
下面是这几个流程的解释,来自 知乎美图,写得挺好的,我这里就粘过来了,不自己写了。
算法的核心三个阶段分别是 pre-prepare 阶段(预准备阶段),prepare 阶段(准备阶段), commit 阶段(提交阶段)。图中的C代表客户端,0,1,2,3 代表节点的编号,打叉的3代表可能是故障节点或者是问题节点,这里表现的行为就是对其它节点的请求无响应。0 是主节点。整个过程大致是如下:
首先,客户端向主节点发起请求,主节点 0 收到客户端请求,会向其它节点发送 pre-prepare 消息,其它节点就收到了pre-prepare 消息,就开始了这个核心三阶段共识过程了。
- Pre-prepare 阶段:节点收到 pre-prepare 消息后,会有两种选择,一种是接受,一种是不接受。什么时候才不接受主节点发来的 pre-prepare 消息呢?一种典型的情况就是如果一个节点接受到了一条 pre-pre 消息,消息里的 v 和 n 在之前收到里的消息是曾经出现过的,但是 d 和 m 却和之前的消息不一致,或者请求编号不在高低水位之间,这时候就会拒绝请求。拒绝的逻辑就是主节点不会发送两条具有相同的 v 和 n ,但 d 和 m 却不同的消息。
- Prepare 阶段:节点同意请求后会向其它节点发送 prepare 消息。这里要注意一点,同一时刻不是只有一个节点在进行这个过程,可能有 n 个节点也在进行这个过程。因此节点是有可能收到其它节点发送的 prepare 消息的。在一定时间范围内,如果收到超过 2f 个不同节点的 prepare 消息,就代表 prepare 阶段已经完成。
- Commit 阶段:于是进入 commit 阶段。向其它节点广播 commit 消息,同理,这个过程可能是有 n 个节点也在进行的。因此可能会收到其它节点发过来的 commit 消息,当收到 2f+1 个 commit 消息后(包括自己),代表大多数节点已经进入 commit 阶段,这一阶段已经达成共识,于是节点就会执行请求,写入数据。
处理完毕后,节点会返回消息给客户端,这就是 pbft 算法的全部流程。
1
2
3
4
5
6
注解:
V:当前视图的编号。视图的编号是什么意思呢?比如当前主节点为 A,视图编号为 1,如果主节点换成 B,那么视图编号就为 2,这个概念和 raft 的 term 任期是很类似的。
N:当前请求的编号。主节点收到客户端的每个请求都以一个编号来标记。
M:消息的内容
d或D(m):消息内容的摘要
i: 节点的编号
对于 pre-prepare 阶段,主节点广播 pre-prepare 消息给其它节点即可,因此通信次数为 n-1 ;对于 prepare 阶段,每个节点如果同意请求后,都需要向其它节点再 广播 parepare 消息,所以总的通信次数为 n*(n-1),即 n^2-n ;对于 commit 阶段,每个节点如果达到 prepared 状态后,都需要向其它节点广播 commit 消息,所以总的通信次数也为 n*(n-1) ,即 n^2-n 。所以总通信次数为 (n-1)+(n^2-n)+(n^2-n) ,即 2n^2-n-1 ,因此pbft算法复杂度为 O(n^2) 。
OK,到这里,想说的就差不多了,至于 PBFT 的高低水位和视图更改等,大家如果感兴趣,可以看看 知乎美图 的这篇文章,介绍挺详细。
这篇文章主要是总结下自己对 CFT、BFT 的一些算法的理解,希望可以帮到大家,就到这里吧。
参考
https://www.youtube.com/watch?v=_e4wNoTV3Gw
http://thesecretlivesofdata.com/raft/
https://yeasy.gitbooks.io/blockchain_guide/content/distribute_system/bft.html
https://yeasy.gitbooks.io/blockchain_guide/content/distribute_system/paxos.html
https://zhuanlan.zhihu.com/p/35847127
http://blog.liqilei.com/bai-zhan-ting-gong-shi-suan-fa-zhi-pbftjie-xi/
https://www.jianshu.com/p/78e2b3d3af62
https://blog.csdn.net/kojhliang/article/details/71515199
https://hk.saowen.com/a/9341619d25e086ac42772e8b429078bbe8227615792b3508cb54a431d430df1c