
这篇文章逐步介绍YOLOv1-v3,水平有限,如有错误,欢迎指正。
一些基本概念
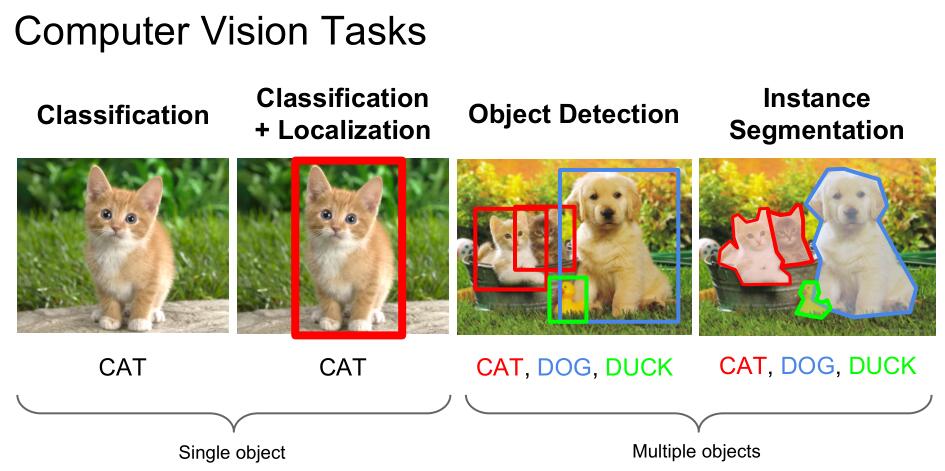
Object Detection
目标检测,包含目标的分割和识别,不只是标记出目标在图片中的位置,还要识别出目标的类别。
![]()
R-CNN ( Region CNN )
一种目标检测算法,一般的 R-CNN 流程如下:
- 将一张图像生成多个候选区域
- 对每个候选区域,使用深度网络提取特征
- 特征送入SVM 分类器,判断目标分类
- 对候选框进行修正,得到最终的结果
mAP
这个是作者衡量模型性能的一个主要指标。
\[Precision_c = \frac {N(TruePositive_{c})} {N(TotalObjects_{c})}\] \[AveragePrecision_c = \frac {\sum Precision_c} {N(TotalImages_c)}\] \[MeanAveragePrecision = \frac {\sum AveragePrecision_c} {N(Classes)}\]
YOLO 的特点
YOLO 是 you only look once 的缩写,YOLO 从影像输入到输出预测结果仅靠一个 CNN 网络来实现,这点与 R-CNN 很不同。正因为此,YOLO 是一个实时的目标检测算法,可以达到 45 帧/秒(Fast YOLO 可以达到 155 帧/秒),可用在视频实时检测上。
优点
- 快速,可以实时检测。
- 背景误检率(background errors)低。
- 通用性强。
YOLO 的基本思想
YOLO 将输入图像分成 \(S*S\) 个格子,如果某个物体的中心坐标落入到某个格子中,那么这个格子就负责检测出这个物体。 这点在图像预处理上体现为,一个物体可能占据了多个格子,但是只有物体中心所在的格子才被标注为“存在物体”。

YOLOv1
每个格子预测5个数值,分别为 x, y, w, h, confidence
x, y: 物体的中心相对于格子边界的位置
w, h: 物体的长宽相对于整个图像的比例
confidence: 格子检测到物体的置信度,作者定义的公式为 \(Pr(Object)*IOU^{truth}_{pred}\),如果不存在物体,整个值应为0,如果存在物体,那么这个值应为预测 box 和真实框的 box 的 IOU。
这里需要说明的是,这个confidence的公式,是作者的预期,在实际模型中,是没有这个公式的
另外在 YOLOv3 中,模型不再直接预测 x,y,w,h
每个格子预测只一个分类,采用下面这个公式
\[Pr(Class_i|Object)*Pr(Object)*IOU^{truth}_{pred}=Pr(Class_i)*IOU^{truth}_{pred}\]这点与 YOLOv3 也不同,在 v3 中,每个格子的每个 box都可以单独预测一个分类,这样可以检测出重叠的物体
因此模型一共输出 \(S*S*(B*5+C)\) 个数值
**在 YOLOv2 YOLOv3 中为 \(S*S*B*(5+C)\) **
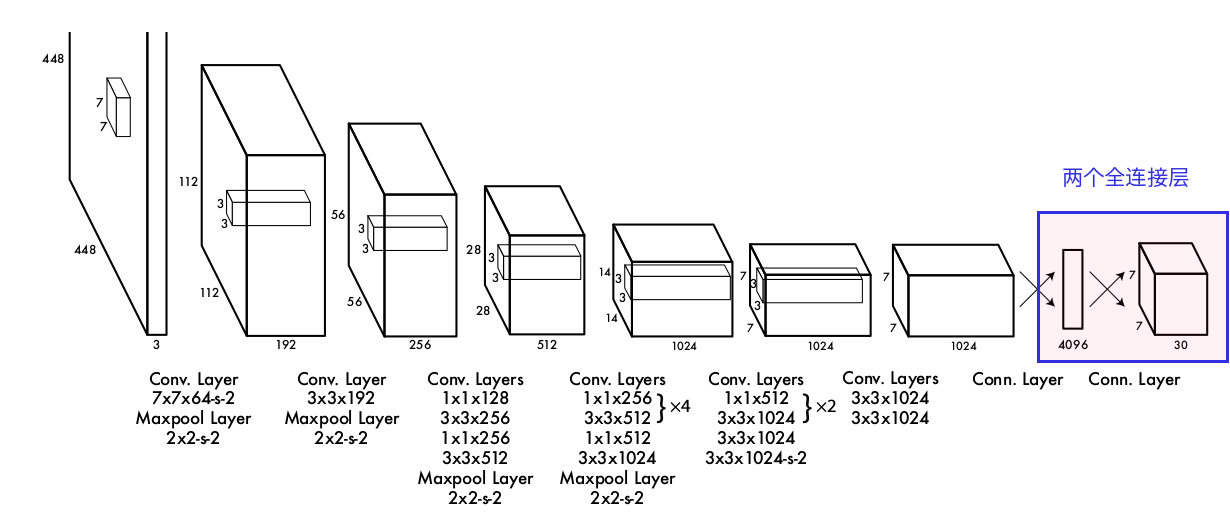
网络设计
整体参考GoogLeNet,24个卷积层和2个全连接层
![]()
注意这里有两个全连接层,在v2开始,取消了全连接层,使用卷积代替
训练流程
作者先取了模型中的前20个卷积层,然后在后面增加了一个平均池化层和一个全连接层,组成了一个新的网络,用1000分类的 ImageNet 来训练网络,作者在 TitanX 上训练了一个礼拜。。
然后删除掉新增的池化层和全连接层,使用原本的网络,前20层的参数保持训练后的参数,后4层和2个全连接的参数随机初始化。并且为了效果更好,将输入从224*224提升到了448*448。
这里也是正因为有全连接层,所以在更改了输入图像的大小的时候,全连接层的参数就没法使用了,也就必须删除掉
loss
loss 作者有些特殊设计,作者为包含物体和不包含物体的 confidence loss 增加了权重,包含物体的权重更大,这样不包含物体的 loss 对整体 loss 的影响就小了,这很好理解,因为不含物体的格子太多了,而包含物体的格子很少,我们应该增加少的格子的权重,况且这部分格子我们更关心。
![]()
另外一些细节
作者在第一个全连接层后使用了 dropout 层,并且使用了数据扩展,为了防止过拟合。
从 YOLOv2 开始,作者使用 Batch Normalization,因为其有正则作用,所以作者去掉了 dropout 层
一些不足
- 因为每个格子只能预测一个分类的两个 box,所以在离得很近的物体上,效果不好。在YOLOv3中增加了 box,而且每个 box 可以有不同类别,这点有所改善,但不能说解决
- 泛化性能不好。这个我觉得还好
- 一个小的 error,在大的 box 和小的 box 上对 IOU 的影响不同,但是由于 loss 的定义方式,无法体现出来。这个导致了 YOLO 会犯定位错误的问题。这个在 YOLOv3 上,好像也没解决
剩下的是一些对比数据,YOLO 综合来看还是非常牛的,并且得益于全连接层,使 YOLO 可以看到整张图像,Background 的错误大概只有 Fast R-CNN 的 1/3。
不能理解的是,v2 开始作者就取消了全连接层,那么 YOLO 如何能解决 Background 的问题? 后来的论文里,也没再提 Background 的错误率问题
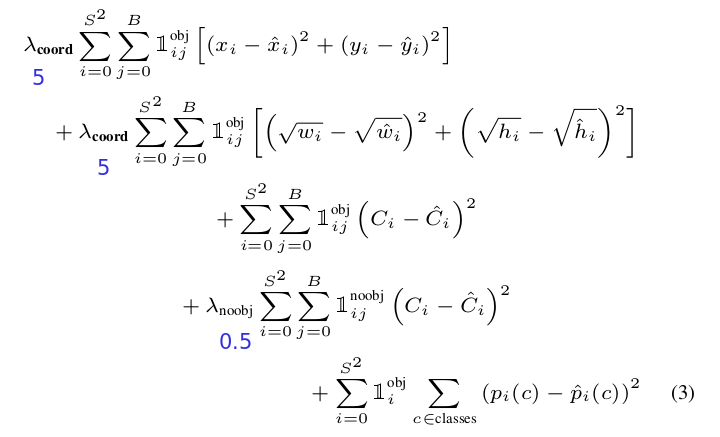
YOLOv2
在这篇论文里,作者介绍了 YOLOv2 和 YOLO9000 两个模型。这两个模型相比于 YOLOv1 都做了一些改进,YOLO9000 上还提出了一种将分类和目标检测数据集混合在一起训练的方式,可以充分利用庞大的分类数据集,让 YOLO 可以检测更多的物体。
YOLOv1 相对于 R-CNN 来说,有标错位置多和召回率低的问题,所以作者主要针对这两个方面进行优化。
Batch Normalization BN 以标准化每层的数据分布,优化深层网络的训练,并且有一定的正则效果。
作者使用 BN,获得了mAP 2%的提升,并且因此去掉了dropout 层。
High Resolution Classifier
YOLOv1 的时候,在转换模型为目标检测的同时,将输入图像从 224*224 提升为 448*448,这使模型需要同时适应分类到目标的转换和像素的提升。
在 YOLOv2 和 9000 中,作者在转换之前,先进行了10epoches 的 448*448 的分类训练,然后才转到目标检测训练,这获得了 mAP 4% 的提升。
Convolutional With Anchor Boxes
作者借鉴 R-CNN 加入了 anchor boxes,anchor boxes 是 预先选择好的一系列 boxes,这个不同于 YOLOv1 中的 boxes。
去掉了全连接层,输入图像从 448 削减到 416,因为作者认为大的物体一般位于图像的中间,所以作者希望输入图像有一个中心点,即像素是奇数。
分类也是每个 box 均有了(YOLOv1 是每个格子一个分类),所以现在模型的输出为 \(S*S*B*(5+C)\) 。
这些改动使 mAP 小幅下降,从 69.5 下降到 69.2,但是召回率从 81% 上升到 88%。
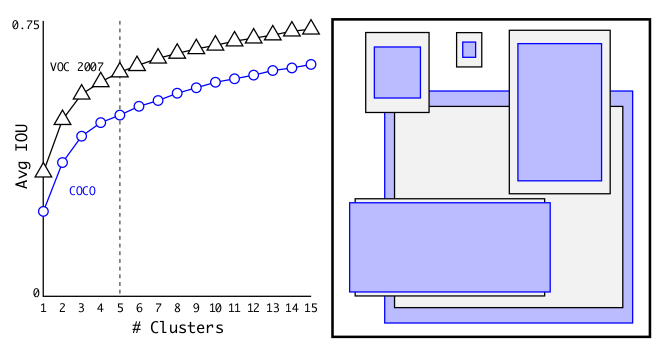
Dimension Clusters
在选择anchor boxes的时候,作者没有手动选择,而是使用的是k-means聚类,分析train set中的所有boxes,然后进行聚类。
作者没有使用殴几里距离,因为对于大boxes会产生更多的error,因为关心的是IOU,所以作者这里使用的是如下这个公式:
\[d(box, centroid) = 1 - IOU(box, centroid)\]![]()
考虑到模型复杂度和高的查全率,作者选择了 5 这个点(“拐点”应该是 3,作者选择的这个点位于“拐点”附近)。
Direct location prediction
作者使用一种新的位置预测方式(YOLOv3中延续了这个方式),这种方式将x, y的取值范围限制在0和1之间,这样中心点就只能位于此格子中,这样使训练前期的稳定性提高。具体的看 YOLOv3 中的介绍。
这种处理方式,可以借鉴
Fine-Grained Features(细粒度特征)
为了提升小物体的检测效果,通过取前面层的输出,并加到现有层上,预测出的 13*13 包含了更多的细粒度特征。提升了 1% 的性能。
Multi-Scale Training
因为现在没有了全连接层,模型实际上对于输入图像的大小不敏感,为了增加鲁棒性,作者多了多尺寸的训练,尺寸范围从 320 到 608,每10个 epoches 改变一次。
这种方式虽然对输入图像不敏感,但是输出敏感,也就是实际的 y 根据输入图像大小不同,得变化。另外在 YOLOv3 中不再使用了
关于融合detection和classification数据
我觉得,这部分才是这篇论文的重点。下面说的都是 YOLO9000 中特有的技术了
During training we mix images from both detection and classification datasets. When our network sees an image labelled for detection we can backpropagate based on the full YOLOv2 loss function. When it sees a classification image we only backpropagate loss from the classification specific parts of the architecture.
When it sees a classification image we only backpropagate classification loss. To do this we simply find the bounding box that predicts the highest probability for that class and we compute the loss on just its predicted tree.
这里将两个数据集的数据融合到了一起,如果取到的是分类的数据,那么就只训练模型中分类部分的参数,找到所有boxes中预测为当前分类的最高可能性,用这个来计算error,并更新网络。如果取到的是目标数据,那么就正常训练整个模型。
但是由于分类和目标的数据标签不一样,不是排他的,所以作者没有使用softmax而是使用了sigmoid,而且引入了WordTree
下面的是我关于WordTree和9000模型的理解:
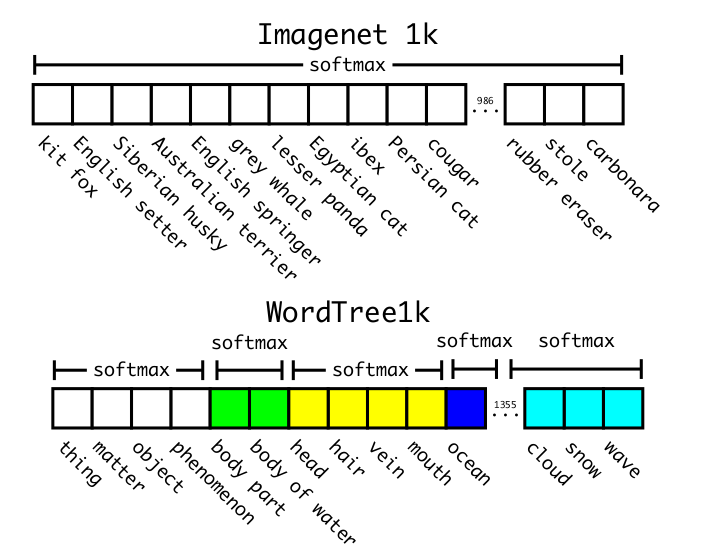
To compute the conditional probabilities our model predicts a vector of 1369 values and we compute the softmax over all sysnsets that are hyponyms of the same concept, see Figure 5. 原来ImageNet1000模型在计算分类的时候,都是直接使用的softmax,来做1000分类预测,但是这里不是了,这里也使用了softmax,不过只是对当前子类做的,看下两图
![]()
这里wave,snow,cloud都是同一个子类的,softmax是针对这3个类别来做的。
![]()
When our network sees a detection image we backpropagate loss as normal. For classification loss, we only backpropagate loss at or above the corresponding level of the label. For example, if the label is “dog” we do assign any error to predictions further down in the tree, “German Shepherd” versus “Golden Retriever”, because we do not have that information.
To do this we simply find the bounding box that predicts the highest probability for that class and we compute the loss on just its predicted tree.
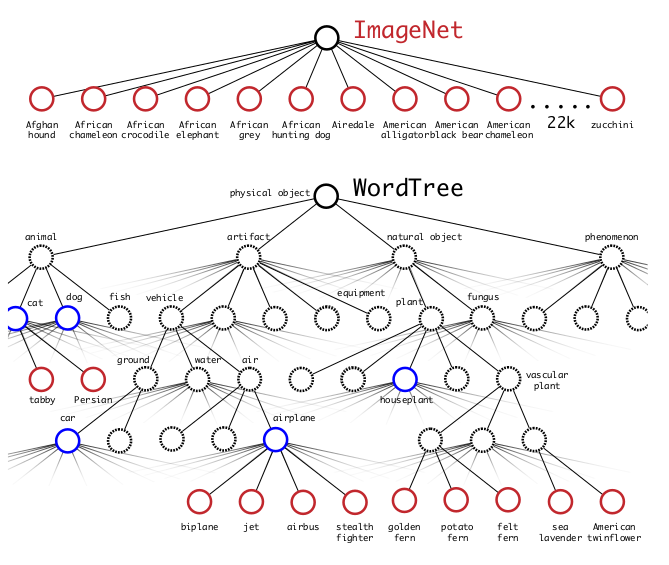
这两个可以一起说。作者的算法中,对于分类图像,找到所有boxes中预测为当前分类的最高可能性的那个box,在这个box的分类计分中,只计算WordTree中标签同层和上层的loss,而不管下层的,比如标签为dog,只需要计算同层的fish,cat和上层的animal,artifact,natualobject,phenomenon,不用计算“German Shepherd”“Golden Retriever”这种。
对于目标检测图像,就按照正常的loss算法来计算。
We traverse the tree down, taking the highest confidence path at every split until we reach some threshold and we predict that object class.
Performance degrades gracefully on new or unknown object categories. For example, if the network sees a picture of a dog but is uncertain what type of dog it is, it will still predict “dog” with high confidence but have lower confidences spread out among the hyponyms. 这两个一起说。
在预测类别的时候,因为模型得到的是包含树中所有节点值的一个向量,那么怎么找出可能性最大的类别呢?
肯定不是直接计算所有节点的绝对概率,然后选最大的。因为作者计算分类的绝对概率的时候,是按照树的分支来一步步乘条件概率得到的,那么就是分支越深,绝对概率就会越小,这样的话,根节点一定是概率最大的。
所以这里肯定需要一个搜索策略,作者使用的策略是贪婪算法,每次都找最大可能性的分支,不断找下去,直到达到一个终止条件(threshold)。
这种处理方式的好处就是,比如如果图片是一个之前从没见过的狗的分类,那么可能系统找到dog这个分类,就不继续往下找了,那么就预测这个图片为dog。
The corresponding WordTree for this dataset has 9418 classes. ImageNet is a much larger dataset so we balance the dataset by oversampling COCO so that ImageNet is only larger by a factor of 4:1.
这里提到的是由于ImageNet比COCO大很多,所以当融合这两个数据集的时候,COCO的数据占比就非常小,为了平衡比例,作者对COCO数据集使用了过采样,使比例达到4:1.
Using this dataset we train YOLO9000. We use the base YOLOv2 architecture but only 3 priors instead of 5 to limit the output size.
作者将boxes从5个减少到3个,这个可能是因为原来每个box预测的是20分类,现在是9000+分类,如果再使用5个box,参数就会太多。
Conversely, COCO does not have bounding box label for any type of clothing, only for person, so YOLO9000 struggles to model categories like “sunglasses” or “swimming trunks”.
这里提到的是YOLO9000,在检测没见过的衣服的效果比没见过的动物的效果要差很多,是因为COCO数据集中,关于衣服的数据很少。
YOLOv3
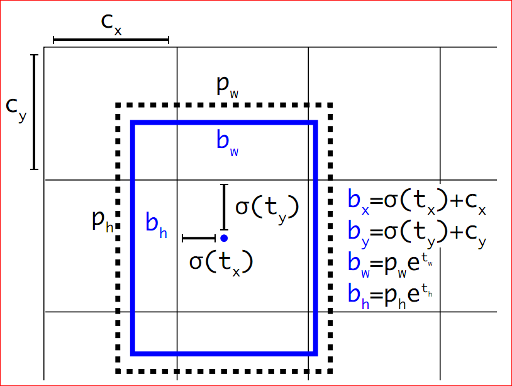
During training we use sum of squared error loss. If the ground truth for some coordinate prediction is ^ t* our gradient is the ground truth value (computed from the ground truth box) minus our prediction: ^ t* t*. This ground truth value can be easily computed by inverting the equations above.
![]()
这里是从 YOLOv2 继承来的。
模型的输出是\(t_x, t_y, t_w, t_h\),计算loss时,换算真实box的这四个参数,和模型得出数值计算均方差。
(但是这里在求bx by的时候,在sigmoid之后使用均方差会使模型非凸,容易陷入局部最小值,查看了一些别人的代码,这里有的使用的是交叉熵)
\(b_x = \sigma(t_x) + c_x\)这种表达式,由于\(\sigma\)取值0-1,所以限制了物体中心点的预测范围(在grid内部),相比于RPN中的中心点可以位于任意位置,这样使模型训练变得简单、稳定。
Each box predicts the classes the bounding box may contain using multilabel classification. We do not use a softmax as we have found it is unnecessary for good performance, instead we simply use independent logistic classifiers. During training we use binary cross-entropy loss for the class predictions.
This formulation helps when we move to more complex domains like the Open Images Dataset [7]. In this dataset there are many overlapping labels (i.e. Woman and Person). Using a softmax imposes the assumption that each box has exactly one class which is often not the case. A multilabel approach better models the data.
作者这里对于输出的“存在物体”和“物体分类”的结果,都采用的sigmoid来计算,而没有使用softmax,而且使用交叉熵作为loss函数。
这么做的原因是,作者发现一是使用softmax没发现性能提升,二是在一些复杂的数据集的时候,数据的标签不能保证是独立的,比如女人和人,是非互相独立的,而softmax总是假设标签相互独立,所以不适合。
YOLOv3 predicts boxes at 3 different scales. Our system extracts features from those scales using a similar concept to feature pyramid networks [8]. From our base feature extractor we add several convolutional layers. The last of these predicts a 3-d tensor encoding bounding box, objectness, and class predictions. In our experiments with COCO [10] we predict 3 boxes at each scale so the tensor is N*N*[3*(4+ 1+ 80)] for the 4 bounding box offsets, 1 objectness prediction, and 80 class predictions.
作者这里使用了3个scale,就是作者同时预测了13*13,26*26,52*52三种grid,不同大小的grid,适用于检测不同大小的物体,三种grid预测出的所有box集合在一起,然后通过non_max_suppression来找到最好的box。
We still use k-means clustering to determine our bounding box priors. We just sort of chose 9 clusters and 3 scales arbitrarily and then divide up the clusters evenly across scales. On the COCO dataset the 9 clusters were: (10 × 13), (16 × 30), (33 × 23), (30 × 61), (62 × 45), (59 × 119), (116 × 90), (156 × 198), (373 × 326).
这里作者针对不同的scale,准备了不同的anchor boxes。boxes的选择方式,还是采用的K-means。
先取出数据集中的一些图像的一些boxes,然后进行聚类,得到9个boxes,然后将这9个boxes,划分为3scale。
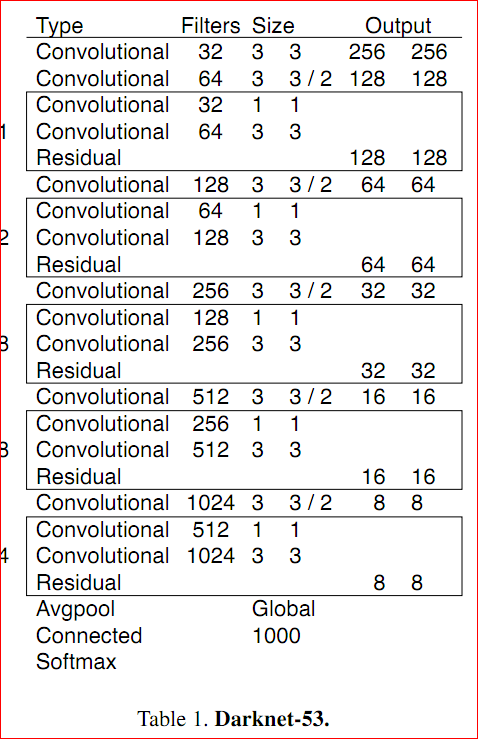
darknet53模型
![]()
这个是作者用来训练分类任务的模型,借鉴于VGG,在物体检测任务里,作者使用了分类任务的训练参数,在上图模型上,删除了最后3层,加入了一些额外的卷积层,然后在此基础上训练物体检测任务。
分类任务,由于有大量的标记数据,可以训练出能够准确分类的模型。物体检测任务在此基础上继续训练模型的检测物体的能力,只需要少量的物体检测数据,这样可以同时达到准确分类和检测物体的目的。这也是一种转移学习。
数据集中的数据,是如何转换成训练数据的?
数据集中的数据给出的是物体的分类和物体框的左上右下角的坐标,单位是像素。
- 先将物体框的顶角坐标转化为中心点坐标和长宽。
- 然后将坐标和长宽,转化为图像总长宽的比例系数。
- 计算loss的时候,再将比例系数,转化为t。
论文下载
- yolov1: https://arxiv.org/abs/1506.02640
- yolov2&9000: https://arxiv.org/abs/1612.08242
- yolov3: https://arxiv.org/abs/1804.02767
代码下载
darknet 这个是官方的框架,用 c 写的,支持 GPU 训练。
参考官网的介绍,https://pjreddie.com/darknet/yolo/
一些感想
之前看吴恩达的深度学习教程的时候,就了解了 YOLO 的基础思想和实现方式,但是当自己从头开始看论文,才发现自己很多地方其实是一知半解。
模型从v1到v3的逐步优化过程,很有借鉴意义,尤其是 YOLO9000 的融合多数据集的部分,真是让人惊讶。
如有问题欢迎提问,如有错误欢迎指正。